In my previous post, Teaching Apps how to Learn with Spicepods, I introduced Spicepods as packages of configuration that describe an application's data-driven goals and how it should learn from data. To leverage Spice.ai in your application, you can author a Spicepod from scratch or build upon one fetched from the spicerack.org registry. In this post, we'll walk through the creation and authoring of a Spicepod step-by-step from scratch.
As a refresher, a Spicepod consists of:
- A required YAML manifest that describes how the pod should learn from data
- Optional seed data
- Learned model/state
- Performance telemetry and metrics
We'll create the Spicepod for the ServerOps Quickstart, an application that learns when to optimally run server maintenance operations based upon the CPU-usage patterns of a server machine.
We'll also use the Spice CLI, which you can install by following the Getting Started guide or Getting Started YouTube video.
Modern web development workflows often include a file watcher to hot-reload so you can iteratively see the effect of your change with a live preview.
Spice.ai takes inspiration and enables a similar Spicepod manifest authoring experience. If you first start the Spice.ai runtime in your application root before creating your Spicepod, it will watch for changes and apply them continuously so that you can develop in a fast, iterative workflow.
You would normally do this by opening two terminal windows side-by-side, one that runs the runtime using the command spice run and one where you enter CLI commands. In addition, developers would open the Spice.ai dashboard located at http://localhost:8000 to preview changes they make.

The easiest way to create a Spicepod is to use the Spice.ai CLI command: spice init <Spicepod name>. We'll make one in the ServerOps Quickstart application called serverops.

The CLI saves the Spicepod manifest file in the spicepods directory of your application. You can see it created a new serverops.yaml file, which should be included in your application and be committed to your source repository. Let's take a look at it.

The initialized manifest file is very simple. It contains a name and three main sections being:
- dataspaces
- actions
- training
We'll walk through each of these in detail, and as a Spicepod author, you can always reference the documentation for the Spicepod manifest syntax.
You author and edit Spicepod manifest files in your favorite text editor with a combination of Spice.ai CLI helper commands. We eventually plan to have a VS Code extension and dashboard/portal editing abilities to make this even easier.
To build an intelligent, data-driven application, we must first start with data.
A Spice.ai dataspace is a logical grouping of data with definitions of how that data should be loaded and processed, usually from a single source. A combination of its data source and its name identifies it, for example, nasdaq/msft or twitter/tweets. Read more about Dataspaces in the Core Concepts documentation.
Let's add a dataspace to the Spicepod manifest to load CPU metric data from a CSV file. This file is a snapshot of data from InfluxDB, a time-series database we like.

We can see this dataspace is identified by its source hostmetrics and name cpu. It includes a data section with a file data connector, the path to the file, and a data processor to know how to process it. In addition, it defines a single measurement usage_idle under the measurements section, which is a measurement of CPU load. In Spice.ai, measurements are the core primitive the AI engine uses to learn and is always numerical data. Spice.ai includes a growing library of community contributable data connectors and data processors you can consist of in your Spicepod to access data. You can also contribute your own.
Finally, because the data is a snapshot of live data loaded from a file, we must set a Spicepod epoch_time that defines the data's start Unix time.
Now we have a dataspace, called hostmetrics/cpu, that loads CSV data from a file and processes the data into a usage_idle measurement. The file connector might be swapped out with the InfluxDB connector in a production application to stream real-time CPU metrics into Spice.ai. And in addition, applications can always send real-time data to the Spice.ai runtime through its API with a simple HTTP POST (and in the future, using Web Sockets and gRPC).
Now that the Spicepod has data, let's define some data-driven actions so the ServerOps application can learn when is the best time to take them. We'll add three actions using the CLI helper command, spice action add.
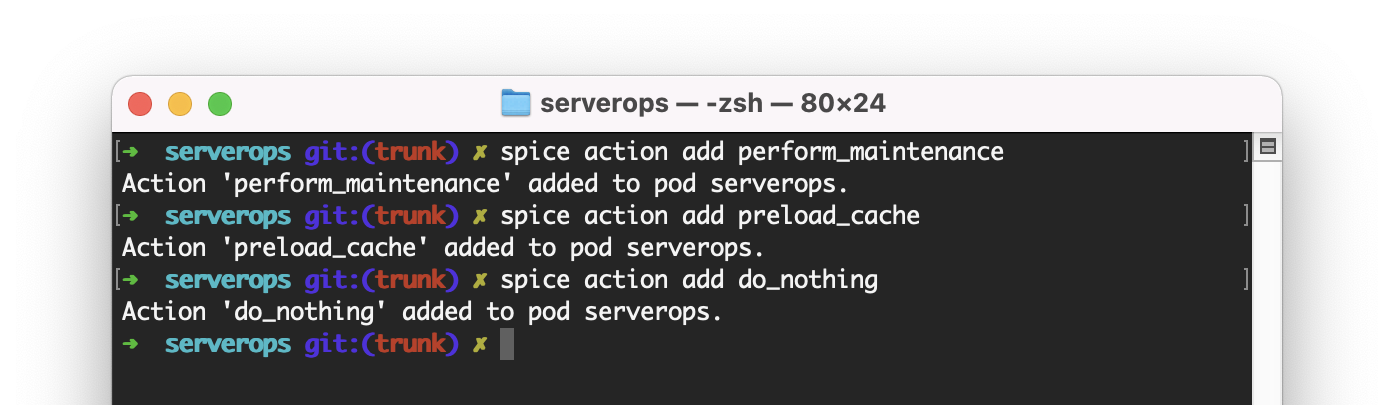
And in the manifest:

The Spicepod now has data and possible actions, so we can now define how it should learn when to take them. Similar to how humans learn, we can set rewards or punishments for actions taken based on their effect and the data. Let's add scaffold rewards for all actions using the spice rewards add command.

We now have rewards set for each action. The rewards are uniform (all the same), meaning the Spicepod is rewarded the same for each action. Higher rewards are better, so if we change perform_maintenance to 2, the Spicepod will learn to perform maintenance more often than the other actions. Of course, instead of setting these arbitrarily, we want to learn from data, and we can do that by referencing the state of data at each time-step in the time-series data as the AI engine trains.

The rewards themselves are just code. Currently, we currently support Python code, either inline or in a .py external code file and we plan to support several other languages. The reward code can access the time-step state through the prev_state and new_state variables and the dataspace name. For the full documentation, see Rewards.
Let's add this reward code to perform_maintenance, which will reward performing maintenance when there is low CPU usage.
cpu_usage_prev = 100 - prev_state.hostmetrics_cpu_usage_idle
cpu_usage_new = 100 - new_state.hostmetrics_cpu_usage_idle
cpu_usage_delta = cpu_usage_prev - cpu_usage_new
reward = cpu_usage_delta / 100
This code takes the CPU usage (100 minus the idle time) deltas between the previous time state and the current time state, and sets the reward to be a normalized delta value between 0 and 1. When the CPU usage is moving from higher cpu_usage_prev to lower cpu_usage_low, its a better time to run server maintenance and so we reward the inverse of the delta. E.g. 80% - 50% = 30% = 0.3. However, if the CPU moves lower to higher, 50% - 80% = -30% = -0.3, it's a bad time to run maintenance, so we provide a negative reward or "punish" the action.

Through these rewards and punishments and the CPU metric data, the Spicepod will when it is a good time to perform maintence and be the decision engine for the ServerOps application. You might be thinking you could write code without AI to do this, which is true, but handling the variety of cases, like CPU spikes, or patterns in the data, like cyclical server load, would take a lot of code and a development time. Applying AI helps you build faster.
The manifest now has defined data, actions, and rewards. The Spicepod can get data to learn which actions to take and when based on the rewards provided.
If the Spice.ai runtime is running, the Spicepod automatically trains each time the manifest file is saved. As this happens reward performance can be monitored in the dashboard.
Once a training run completes, the application can query the Spicepod for a decision recommendation by calling the recommendations API http://localhost:8000/api/v0.1/pods/serverops/recommendation. The API returns a JSON document that provides the recommended action, the confidence of taking that action, and when that recommendation is valid.
In the ServerOps Quickstart, this API is called from the server maintenance PowerShell script to make an intelligent decision on when to run maintenance. The ServerOps Sample, which uses live data, can be continuously trained to learn and adapt even as the live data changes due to load patterns changing.
The full Spicepod manifest from this walkthrough can be added from spicerack.org using the spice add quickstarts/serverops command.
Leveraging Spice.ai to be the decision engine for your server maintenance application helps you build smarter applications, faster that will continue to learn and adapt over time, even as usage patterns change over time.
Building intelligent apps that leverage AI is still way too hard, even for advanced developers. Our mission is to make this as easy as creating a modern web page. If the vision resonates with you, join us!
Our Spice.ai Roadmap is public, and now that we have launched, the project and work are open for collaboration.
If you are interested in partnering, we'd love to talk. Try out Spice.ai, email us "hey," get in touch on Slack, or reach out on Twitter.
We are just getting started! 🚀
Luke