Spice v1.7.0 (Sep 23, 2025)

Announcing the release of Spice v1.7.0! ⚡
Spice v1.7.0 upgrades to DataFusion v49 for improved performance and query optimization, introduces real-time full-text search indexing for CDC streams, EmbeddingGemma support for high-quality embeddings, new search table functions powering the /v1/search API, embedding request caching for faster and cost-efficient search and indexing, and OpenAI Responses API tool calls with streaming. This release also includes numerous bug fixes across CDC streams, vector search, the Kafka Data Connector, and error reporting.
What's New in v1.7.0
DataFusion v49 Highlights
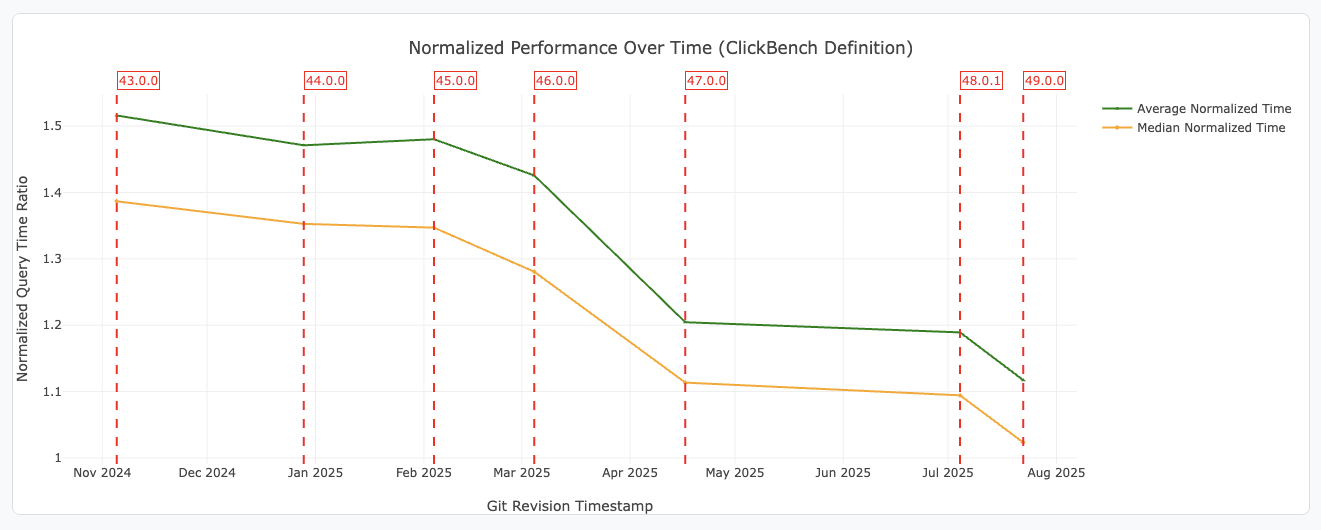 Source: DataFusion 49.0.0 Release Blog.
Source: DataFusion 49.0.0 Release Blog.
Performance Improvements 🚀
- Equivalence System Upgrade: Faster planning for queries with many columns, enabling more sophisticated sort-based optimizations.
- Dynamic Filters & TopK Pushdown: Queries with
ORDER BYandLIMITnow use dynamic filters and physical filter pushdown, skipping unnecessary data reads for much faster top-k queries. - Compressed Spill Files: Intermediate files written during sort/group spill to disk are now compressed, reducing disk usage and improving performance.
- WITHIN GROUP for Ordered-Set Aggregates: Support for ordered-set aggregate functions (e.g.,
percentile_disc) withWITHIN GROUP. - REGEXP_INSTR Function: Find regex match positions in strings.
Spice Runtime Highlights
EmbeddingGemma Support: Spice now supports EmbeddingGemma, Google's state-of-the-art embedding model for text and documents. EmbeddingGemma provides high-quality, efficient embeddings for semantic search, retrieval, and recommendation tasks. You can use EmbeddingGemma via HuggingFace in your Spicepod configuration:
Example spicepod.yml snippet:
embeddings:
- from: huggingface:huggingface.co/google/embeddinggemma-300m
name: embeddinggemma
params:
hf_token: ${secrets:HUGGINGFACE_TOKEN}
Learn more about EmbeddingGemma in the official documentation.
POST /v1/search API Use Search Table Functions: The /v1/search API now uses the new text_search and vector_search Table Functions for improved performance.
Embedding Request Caching: The runtime now supports caching embedding requests, reducing latency and cost for repeated content and search requests.
Example spicepod.yml snippet:
runtime:
caching:
embeddings:
enabled: true
max_size: 128mb
item_ttl: 5s
See the Caching documentation for details.
Real-Time Indexing for Full Text Search: Full Text search indexing is now supported for connectors that enable real-time changes, such as Debezium CDC streams. Adding a full-text index on a column with refresh_mode: changes works as it does for full/append-mode refreshes, enabling instant search on new data.
Example spicepod.yml snippet:
datasets:
- from: debezium:cdc.public.question
name: questions
acceleration:
enabled: true
engine: duckdb
primary_key: id
refresh_mode: changes # Use 'changes'
params: *kafka_params
columns:
- name: title
full_text_search:
enabled: true # Enable full-text-search indexing
row_id:
- id
OpenAI Responses API Tool Calls with Streaming: The OpenAI Responses API now supports tool calls with streaming, enabling advanced model interactions such as web_search and code_interpreter with real-time response streaming. This allows you to invoke OpenAI-hosted tools and receive results as they are generated.
Learn more in the OpenAI Model Provider documentation.
Runtime Output Level Configuration: You can now set the output_level parameter in the Spicepod runtime configuration to control logging verbosity in addition to the existing CLI and environment variable support. Supported values are info, verbose, and very_verbose. The value is applied in the following priority: CLI, environment variables, then YAML configuration.
Example spicepod.yml snippet:
runtime:
output_level: info # or verbose, very_verbose
For more details on configuring output level, see the Troubleshooting documentation.
Bug Fixes
Several bugs and issues have been resolved in this release, including:
- CDC Streams: Fixed issues where
refresh_mode: changescould prevent the Spice runtime from becoming Ready, and improved support for full-text indexing on CDC streams. - Vector Search: Fixed bugs where vector search HTTP pipeline could not find more than one IndexedTableProvider, and resolved errors with field mismatches in
vector_searchUDTF. - Kafka Integration: Improved Kafka schema inference with configurable sample size, improved consumer group persistence for SQLite and Postgres accelerations, and added cooperative mode support.
- Perplexity Web Search: Fixed bug where Perplexity web search sometimes used incorrect query schema (limit).
- Databricks: Fixed issue with unparsing embedded columns.
- Error Reporting: ThrottlingException is now reported correctly instead of as InternalError.
- Iceberg Data Connector: Added support for LIMIT pushdown.
- Amazon S3 Vectors: Fixed ingestion issues with zero-vectors and improved handling when vector index is full.
- Tracing: Fixed vector search tracing to correctly report SQL status.
Contributors
- @Jeadie
- @peasee
- @sgrebnov
- @kczimm
- @phillipleblanc
- @Advayp
- @lukekim
- @ewgenius
- @mach-kernel
- @krinart
- @ChrisTomAlxHitachi
New Contributors
- @ChrisTomAlxHitachi made their first contribution in github.com/spiceai/spiceai/pull/6932 🎉
Breaking Changes
No breaking changes.
Cookbook Updates
- New Spice with Dotnet SDK Recipe - The recipe shows how to query Spice using the Dotnet SDK.
The Spice Cookbook includes 78 recipes to help you get started with Spice quickly and easily.
Upgrading
To upgrade to v1.7.0, use one of the following methods:
CLI:
spice upgrade
Homebrew:
brew upgrade spiceai/spiceai/spice
Docker:
Pull the spiceai/spiceai:1.7.0 image:
docker pull spiceai/spiceai:1.7.0
For available tags, see DockerHub.
Helm:
helm repo update
helm upgrade spiceai spiceai/spiceai
AWS Marketplace:
🎉 Spice is now available in the AWS Marketplace!
What's Changed
Dependencies
- Rust: Upgraded from 1.88.0 to 1.89.0
- DataFusion: Upgraded from 48.0.1 to 49.0.0
- text-embeddings-inference: Upgraded from 1.7.3 to 1.8.2
- twox-hash: Upgraded from 1.6.3 to 2.1.0.
Changelog
- Fix parameterised query planning in DataFusion by @Jeadie in #6942
- fix: Update benchmark snapshots by @app/github-actions in #6944
- refactor: Decouple full text search candidate from UDTF by @peasee in #6940
- fix: Re-enable search integration tests by @peasee in #6930
- Update acknowledgements and spicepod.schema.json by @sgrebnov in #6948
- Add enabling the responses API by @lukekim in #6949
- Post-release housekeeping by @sgrebnov in #6951
- Add missing param in release notes by @Advayp in #6959
- Create comprehensive S3vectors test by @Jeadie in #6903
- Update ROADMAP after v1.6 release by @sgrebnov in #6955
- Update openapi.json by @app/github-actions in #6961
- Add build step for new spiced images in end game template by @Jeadie in #6960
- refactor: Use text search UDTF in v1/search by @peasee in #6962
- Bump Jimver/cuda-toolkit from 0.2.26 to 0.2.27 by @app/dependabot in #6922
- Bump notify from 8.0.0 to 8.2.0 by @app/dependabot in #6924
- Use model2vec for search integration tests for speed by @Jeadie in #6971
- feat: Add initial DuckDB regexp pushdown support by @peasee in #6966
- Bump rustyline from 16.0.0 to 17.0.1 by @app/dependabot in #6976
- Upgrade delta_kernel to
0.14by @phillipleblanc in #6977 - Consistent snapshots for mongodb by @krinart in #6974
- Bump indexmap from 2.10.0 to 2.11.0 by @app/dependabot in #6921
- Fix mongo tests: ignore container_registry() when building image name by @krinart in #6983
- Implement support for s3 tables for glue DataConnector by @krinart in #6981
- Bump serde_json from 1.0.142 to 1.0.143 by @app/dependabot in #6925
- Update build_and_release macOS pipeline to skip updating cmake if installed by @phillipleblanc in #6998
- Mark Kafka Data Connector Alpha quality by @sgrebnov in #6991
- Add v1.6.1 release notes by @lukekim in #7000
- Spice CLI trace: make error friendlier when task_history is disabled by @sgrebnov in #6996
- Warn when runtime or management is added in spicepod dependency by @Jeadie in #6953
- Enable
.datasets[].vectors.params.s3_vectors_distance_metricfor S3 Vectors by @Jeadie in #6982 - Add s3_vectors index support for CDC and Append streams by @sgrebnov in #6986
- Find all vector indexes in v1/search by @Jeadie in #7004
- Fix RRF; reorder by score by @Jeadie in #7007
- Fix for nested VectorScanTableProvider by @krinart in #7017
- Add --sql flag to output SQL query for spice trace by @Jeadie in #7002
- Make web search params engine-specific by @Advayp in #7022
- Add more MTEB benchmark spicepods by @peasee in #7026
- Improve error messaging in tools by @Jeadie in #6895
- Add retry for exporting task history records by @sgrebnov in #7049
- Increase DoPut write timeout for the next batch from 30 to 120 seconds by @sgrebnov in #7054
- Avoid redundant search embedding by @peasee in #7053
- Truncate
text_embedtask_history trace by @sgrebnov in #7050 - Use the UTC offset for the
start_timeandend_timefields in the task history by @ewgenius in #7056 - Update supported versions in SECURITY.md by @Jeadie in #7060
- Add integration test for Kafka S3 Vectors by @sgrebnov in #6988
- Enable parameters to enforce the value is one of several options by @Jeadie in #6984
- feat(iceberg): lakekeeper catalog - add warehouse param to spicepod by @ChrisTomAlxHitachi in #6932
- feat: Add HTTP query concurrency support to testoperator by @peasee in #7025
- Ensure no data does not throw error in v1/search by @Jeadie in #7033
- Bump github.com/spf13/cobra from 1.9.1 to 1.10.1 by @app/dependabot in #7013
- Add QA analytics for 1.6.x releases by @sgrebnov in #7082
- Use env variable for HF cache in model2vec by @Jeadie in #7076
- chore: upgrade to Rust 1.88 by @kczimm in #7077
- Kafka/Debezium: make common errors user-friendlier by @sgrebnov in #7084
- Create Apache Datafusion upgrade issue template by @kczimm in #6800
- No join predicate pushdown on empty results by @Jeadie in #7075
- Bump tract-onnx from 0.21.10 to 0.22.0 by @app/dependabot in #7071
- Bump mongodb from 3.2.4 to 3.3.0 by @app/dependabot in #7073
- Bump indicatif from 0.17.11 to 0.18.0 by @app/dependabot in #7070
- Bump actions/github-script from 7 to 8 by @app/dependabot in #7069
- Bump actions/setup-go from 5 to 6 by @app/dependabot in #7068
- Bump actions/download-artifact from 4 to 5 by @app/dependabot in #7066
- Bedrock: Tool use without inputs must empty Document by @Jeadie in #7036
- Bump github.com/stretchr/testify from 1.10.0 to 1.11.1 by @app/dependabot in #7015
- Bump actions/setup-python from 5 to 6 by @app/dependabot in #7067
- Upgrade dependabot dependencies by @phillipleblanc in #7061
- Bump tempfile from 3.20.0 to 3.21.0 by @app/dependabot in #7018
- Only call 'list_datasets' once, after initial system/user messages by @Jeadie in #7039
- Bump github.com/spf13/pflag from 1.0.7 to 1.0.10 by @app/dependabot in #7062
- Bump actions/checkout from 4 to 5 by @app/dependabot in #7065
- Bump golang.org/x/mod from 0.27.0 to 0.28.0 by @app/dependabot in #7064
- Bump github.com/AzureAD/microsoft-authentication-library-for-go from 1.4.1 to 1.5.0 by @app/dependabot in #7063
- Add friendly message for Kafka operation timeout error, improve code by @sgrebnov in #7088
embedUDF by @mach-kernel in #6967- fix: Update benchmark snapshots by @app/github-actions in #7097
- Fix SF100 benchmark tests dispatch by @sgrebnov in #7098
- chore(logging): add log when iceberg rest catalog fails with ssl cert error by @ChrisTomAlxHitachi in #6909
- Add xxhash support for search/sql results by @krinart in #6978
- Use proper federation in
max_timestamp_dfduring acceleration refresh by @krinart in #7055 - Fix spiced_docker workflows for new actions/download-artifact@v5 behavior by @phillipleblanc in #7108
- Fix spiced_docker workflow by @phillipleblanc in #7111
- Add filter for zero vectors before writing to S3 Vectors by @phillipleblanc in #7110
- Ensure we find vector index when it also has text search by @Jeadie in #7120
- Enable unified traceparent override support for HTTP API by @sgrebnov in #7122
- Fix
ORDER BY: (BytesProcessedExecto avoid pruning ordered execs during physical optimization) by @mach-kernel in #7105 - Fix spiced_docker_nightly workflow by @sgrebnov in #7125
- Add
output_levelto runtime config by @krinart in #7119 - Add tests for xxhash hashers by @krinart in #7124
- Add input option to update snapshots in Integration tests by @Jeadie in #7127
- Fix formatting to improve merges by @lukekim in #7128
- Add tests to nulling logic by @Jeadie in #7113
- Bump chrono from 0.4.41 to 0.4.42 by @app/dependabot in #7131
- Bump ctrlc from 3.4.7 to 3.5.0 by @app/dependabot in #7132
- Search: RRF UDTF by @mach-kernel in #7090
- Update openapi.json by @app/github-actions in #7141
- Bump packages to DF49; resolve incompatibilities by @Jeadie in #7101
- fix: Don't error for chunked columns when vectors are disabled by @peasee in #7150
- Allow bzip2-1.0.6 license in deny.toml by @Jeadie in #7148
- Tune retry settings for Kafka/Debezium connectors by @sgrebnov in #7142
- Update TEI by @Jeadie in #7152
- Use twox-hash version 2.1.2 by @krinart in #7165
- Revert "Use proper federation in
max_timestamp_dfduring acceleration refresh (#7055)" by @phillipleblanc in #7156 - Bump octocrab from 0.44.1 to 0.45.0 by @app/dependabot in #7158
- Bump github.com/spf13/viper from 1.19.0 to 1.21.0 by @app/dependabot in #7130
- Bump keyring from 3.6.2 to 3.6.3 by @app/dependabot in #7157
- fix: Remove keywords from AI document search by @peasee in #7052
- Bump tract-core from 0.21.10 to 0.22.0 by @app/dependabot in #7134
- Update TEI by @Jeadie in #7171
- Update openapi.json by @app/github-actions in #7172
- fix: Ensure vector search UDTF respects the supplied projection by @peasee in #7155
- Bump clap from 4.5.45 to 4.5.47 by @app/dependabot in #7135
- Bump golang.org/x/sys from 0.35.0 to 0.36.0 by @app/dependabot in #7129
- Include 'catalog_id' in Glue catalog parameters by @Jeadie in #7151
- fix: Use head ref from merge group event in pulls-with-spice concurrency group by @peasee in #7175
- Fix lint for xxhash feature by @phillipleblanc in #7176
- Add Kafka-specific metrics for consumer lag and consumed records by @sgrebnov in #7146
- Kafka: persist consumer between restarts with SQLite and PG acceleration by @sgrebnov in #7177
- Kafka: support specifying a target consumer group ID by @sgrebnov in #7178
- Fix timestamp parsing for spice trace by @krinart in #7173
- Support full-text indexing on CDC/append streams by @phillipleblanc in #7180
- Bump iceberg-rust version to include limit push down by @krinart in #7191
- Make full text stream connector more robust by @phillipleblanc in #7193
- fix: Update benchmark snapshots by @app/github-actions in #7179
- Initial changes for SearchIndex by @Jeadie in #7103
- Robustly handle indexing FTS for CDC streams by @phillipleblanc in #7197
- Proper handling/mapping for
ThrottlingExceptionduring embedding calls by @krinart in #7170 - Add spicepod.yml by @lukekim in #7202
- Delta Lake: Support read pruning on timestamp columns using maxValues stats by @sgrebnov in #7203
- feat: Add initial embeddings cache by @peasee in #7194
- Make S3vector a FixedSizeListArray by @Jeadie in #7201
- Fix projection mismatch issues with RRF calling vector search / text search by @mach-kernel in #7200
- feat: Add embeddings cache to all embeddings by @peasee in #7204
- Revert "Make S3vector a FixedSizeListArray (#7201)" by @kczimm in #7210
- Update duckdb version to make ICU statically linked by default by @krinart in #7215
- Change DataType list nullability from true to false by @Jeadie in #7216
- Use
Instant+saturating_subto handle time drift by @krinart in #7212 - Flatten 'IndexedTableProvider' when adding full-text support by @Jeadie in #7219
- Include comments in pulls by @lukekim in #7224
- Add github_max_concurrent_connections = 5 by @lukekim in #7225
- RRF: Fix scoring by @mach-kernel in #7226
- Update RRF search integration snapshots after scoring change by @mach-kernel in #7227
- Make S3vector a FixedSizeListArray by @Jeadie in #7230
- Proper federation during acceleration refresh + datafusion version bump + integration tests by @krinart in #7228
- Use DuckDBDialect for DuckDB non-federated queries by @krinart in #7232
- Move chunking out of
llmsand into new cratechunkingby @Jeadie in #7229 - Remove duplicate pg_port configuration in test by @lukekim in #7233
- Upgrade to Rust 1.89 by @phillipleblanc in #7235
- Catalog connection error: fix connector name from 'iceberg' to 'spice.ai' by @sgrebnov in #7240
- Create PutVectorsSink by @kczimm in #7199
- Benchmark tests: fix API key reference in spicecloud catalog by @sgrebnov in #7239
- Add Dotnet SDK sample to end game template by @sgrebnov in #7238
- Update spicepod.schema.json by @app/github-actions in #7254
- Postgres: Improve Decimals read performance and add Name type support by @sgrebnov in #7255
- Add tests for hybrid search on a vector engine by @Jeadie in #7220
