Spice.ai Open Source
Spice is a SQL query, search, and LLM-inference engine, written in Rust, for data-driven applications and AI agents.
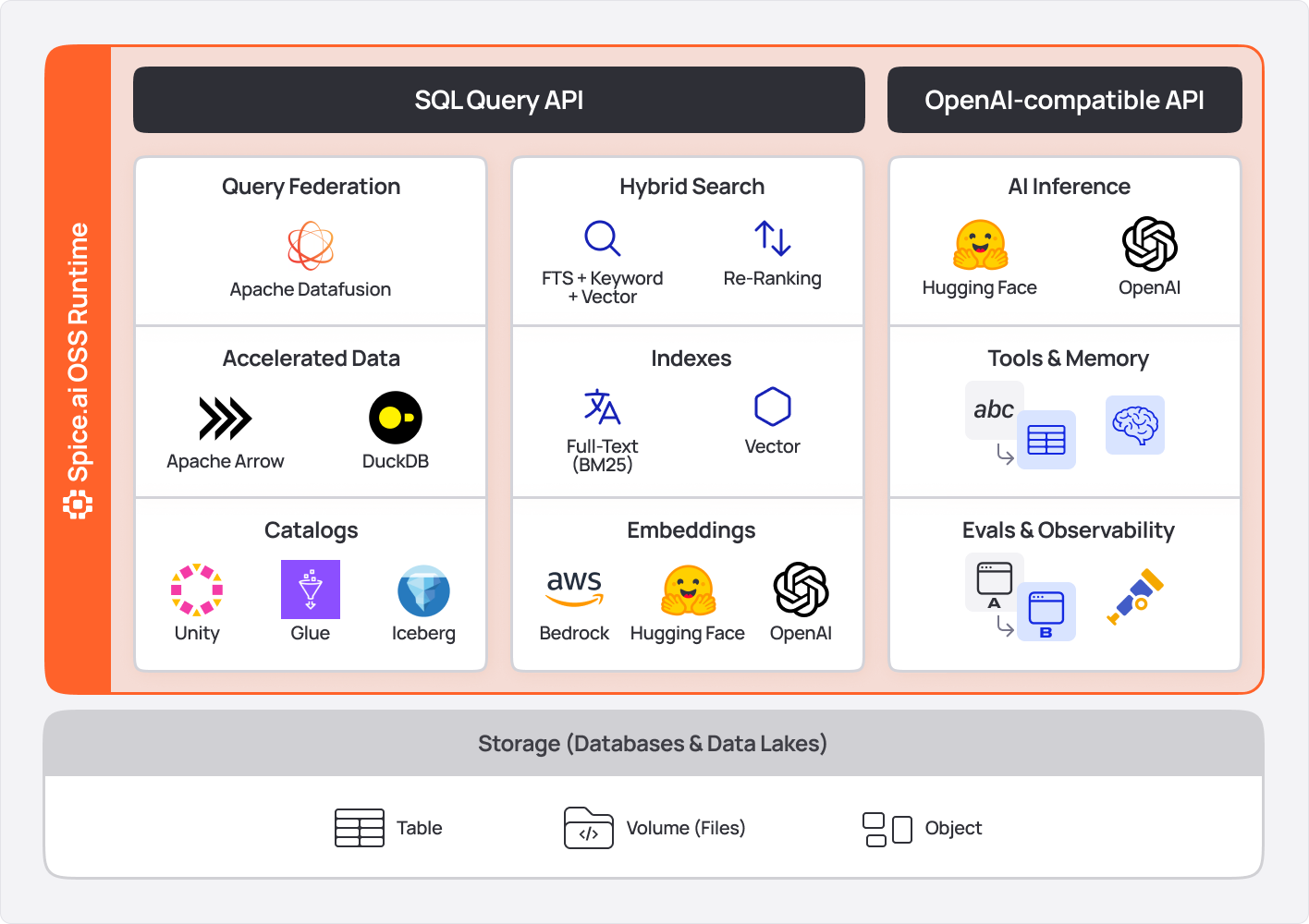
Spice provides four industry-standard APIs in a lightweight, portable runtime (single ~140 MB binary):
- SQL Query & Search APIs: Supports HTTP, Arrow Flight, Arrow Flight SQL, ODBC, JDBC, ADBC, and
vector_searchandtext_searchUDTFs. - OpenAI-Compatible APIs: Provides HTTP APIs for OpenAI SDK compatibility, local model serving (CUDA/Metal accelerated), and hosted model gateway.
- Iceberg Catalog REST APIs: Offers a unified API for Iceberg Catalog.
- MCP HTTP+SSE APIs: Enables integration with external tools via Model Context Protocol (MCP) using HTTP and Server-Sent Events (SSE).
Developers can focus on building data apps and AI agents confidently, knowing they are grounded in data.
Spice is primarily used for:
- Data Federation: SQL query across any database, data warehouse, or data lake. Learn More.
- Data Materialization and Acceleration: Materialize, accelerate, and cache database queries. Read the MaterializedView interview - Building a CDN for Databases.
- Enterprise Search: Keyword, vector, and full-text search with Tantivy-powered BM25 and vector similarity search for structured and unstructured data. Learn More.
- AI Apps and Agents: An AI-database powering retrieval-augmented generation (RAG) and intelligent agents. Learn More.
Spice is built on industry-leading technologies including Apache DataFusion, Apache Arrow, Arrow Flight, SQLite, and DuckDB. If you want to build with DataFusion or DuckDB, Spice provides a simple, flexible, and production-ready engine.
Read the Spice.ai 1.0-stable announcement.
Why Spice?
Spice simplifies building data-driven AI applications and agents by combining SQL query, search, and LLM inference in a single runtime. Instead of stitching together separate databases, caching layers, and AI services, developers deploy Spice alongside their applications to:
- Query any data source with SQL: Join data across PostgreSQL, Snowflake, S3, and other sources without building ETL pipelines.
- Accelerate queries locally: Materialize datasets in-memory or on disk for sub-second query performance, with automatic refresh from source.
- Ground AI in real data: Connect LLMs to datasets through built-in tools so AI responses are based on actual data, not hallucinations.
- Search across data: Run vector, keyword, and hybrid search through SQL functions like
vector_search()andtext_search().
How is Spice different?
- AI-Native Runtime: Combines data query and AI inference in a single engine for data-grounded, accurate AI.
- Application-Focused: Designed for distributed deployment at the application or agent level, often as a 1:1 or 1:N mapping, unlike centralized databases serving multiple apps. Multiple Spice instances can be deployed, even one per tenant or customer.
- Dual-Engine Acceleration: Supports OLAP (Arrow/DuckDB) and OLTP (SQLite/PostgreSQL) engines at the dataset level for flexible performance across analytical and transactional workloads.
- Disaggregated Storage: Separates compute from storage, co-locating materialized working datasets with applications, dashboards, or ML pipelines while accessing source data in its original storage.
- Edge to Cloud Native: Deploy as a standalone instance, Kubernetes sidecar, microservice, or cluster across edge, on-prem, and public clouds. Chain multiple Spice instances for tier-optimized, distributed deployments.
For detailed comparisons with other data query engines and AI frameworks, see How Spice Compares.
Example Use-Cases
Data-Grounded Agentic AI Applications
- OpenAI-Compatible API: Connect to hosted models (OpenAI, Anthropic, xAI) or deploy locally (Llama, NVIDIA NIM). AI Gateway Recipe
- Federated Data Access: Query using SQL and NSQL (text-to-SQL) across databases, data warehouses, and data lakes with advanced query push-down. Federated SQL Query Recipe
- Search and RAG: Perform keyword, vector, and full-text search with Tantivy-powered BM25 and vector similarity search (VSS) integrated into SQL queries using
vector_searchandtext_search. Supports multi-column vector search with reciprocal rank fusion. Amazon S3 Vectors Recipe - LLM Memory and Observability: Store and retrieve history and context for AI agents with visibility into data flows, model performance, and traces. LLM Memory Recipe | Observability Documentation
Database CDN and Query Mesh
- Data Acceleration: Co-locate materialized datasets in Arrow, SQLite, or DuckDB for sub-second queries. DuckDB Data Accelerator Recipe
- Resiliency and Local Dataset Replication: Maintain availability with local replicas of critical datasets. Local Dataset Replication Recipe
- Responsive Dashboards: Enable fast, real-time analytics for frontends and BI tools. Sales BI Dashboard Demo
- Simplified Legacy Migration: Unify legacy systems with modern infrastructure via federated SQL querying. Federated SQL Query Recipe
Retrieval-Augmented Generation (RAG)
- Unified Search with Vector Similarity: Perform efficient vector similarity search across structured and unstructured data, with native support for Amazon S3 Vectors for petabyte-scale storage and querying. Supports distance metrics like cosine similarity, Euclidean distance, or dot product. Amazon S3 Vectors Recipe
- Semantic Knowledge Layer: Define a semantic context model to enrich data for AI. Semantic Model Documentation
- Text-to-SQL: Convert natural language queries into SQL using built-in NSQL and sampling tools. Text-to-SQL Recipe
FAQ
- Is Spice a cache? No, but its data acceleration acts as an active cache, materialization, or prefetcher. Unlike traditional caches that fetch on miss, Spice prefetches and materializes filtered data on intervals, triggers, or via CDC. It also supports results caching.
- Is Spice a CDN for databases? Yes, Spice enables shipping working datasets to where they're accessed most, like data-intensive applications or AI contexts, similar to a CDN. Docs FAQ
Watch a 30-second BI dashboard acceleration demo
See more demos on YouTube.
Intelligent Applications and Agents
Spice enables developers to build data-grounded AI applications and agents by co-locating data and ML models with applications. Read more about the vision for intelligent AI-driven applications.
Connect with Us
- Build with Spice and share feedback at [email protected], Slack, X, or LinkedIn.
- File an issue for bugs or issues.
- Join our team (We're hiring!).
- Contribute code or documentation (CONTRIBUTING.md).
- ⭐️ Star the Spice.ai repo to show support!
