Spice Cayenne Data Accelerator
Spice Cayenne is a data acceleration engine designed for high-performance, scalable query on large-scale datasets. Built on Vortex, a high-performance columnar file format, Spice Cayenne combines columnar storage with in-process metadata management to provide fast query performance to scale to datasets beyond 1TB.
Why Vortex?
Spice Cayenne uses Vortex as its storage format, providing significant performance advantages:
- 100x faster random access reads compared to modern Apache Parquet
- 10-20x faster scans for analytical queries
- 5x faster writes with similar compression ratios
- Zero-copy compatibility with Apache Arrow for efficient data processing
- Extensible architecture with pluggable encoding, compression, and layout strategies
Vortex is a Linux Foundation (LF AI & Data) project under Apache-2.0 license with neutral governance. For performance benchmarks, see bench.vortex.dev.
While DuckDB excels for datasets up to approximately 1TB, Spice Cayenne with Vortex is designed to scale beyond these limits.
Architecture
Spice Cayenne follows a lakehouse architecture inspired by DuckLake, separating metadata management from data storage:
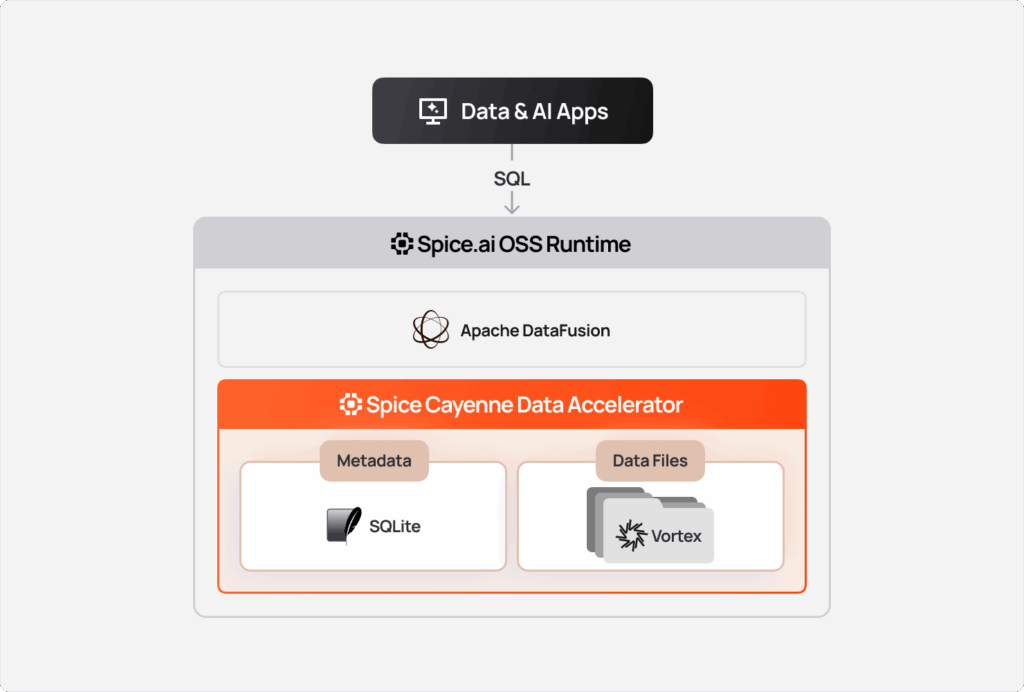
Key Design Principles:
- Virtual Files: Each "file" is a Vortex
ListingTableat a unique directory, enabling append operations and parallel reads - Lazy Statistics: Summary statistics are loaded on-demand for query optimization
- Sequence-based Ordering: Iceberg-style sequence numbers enable upsert semantics without requiring separate tracking of "undeleted" records (rows that were deleted and then re-inserted)
- Pluggable Storage: Data files can be stored locally or in S3 Express One Zone while metadata remains local
Storage Recommendations
For optimal performance, store Cayenne data files on NVMe storage. NVMe provides the lowest latency and highest throughput for the random access patterns that Vortex files require.
Use S3 Express One Zone when persistence of accelerations across restarts is required. S3 Express One Zone adds network latency compared to local NVMe but provides durability. Sharing accelerated data across multiple Spice instances is planned for a future release.
Configuration
To use Spice Cayenne as the data accelerator, specify cayenne as the engine for acceleration. Spice Cayenne supports two storage modes:
mode: file(durable) — data is written as Vortex files on local disk or S3 Express One Zone, with a SQLite/Turso metastore, and the acceleration survives restarts. This is the recommended mode for Cayenne and is used in the examples throughout this page. Themode: file_createandmode: file_updatevariants control how an existing on-disk acceleration is reused or rebuilt on startup.mode: memory(ephemeral) — all data lives fully in RAM with an in-memory metastore; nothing is written to disk. The dataset is ephemeral and reloads from its source on restart (like the Arrow accelerator). Memory mode works for all refresh modes (full/append/changes) and for both keyed and no-primary-key datasets, but does not support partitioned tables (partition_by), and it enforces a hard per-table RAM bound rather than spilling to disk (seecayenne_cdc_mem_tier_max_bytes).
datasets:
- from: spice.ai:path.to.my_dataset
name: my_dataset
acceleration:
engine: cayenne
mode: file
Parameters
Spice Cayenne is configured through two distinct parameter scopes:
- Acceleration parameters are set per dataset under
acceleration.paramsand control how that dataset's accelerated data is stored, compressed, written, and compacted. - Runtime parameters are set once per instance under
runtime.paramsand control engine-global behavior — caches, optimizer rules, and dedicated memory pools — shared by every Cayenne-accelerated dataset.
The two scopes are not interchangeable: setting a runtime parameter under acceleration.params (or a per-dataset parameter under runtime.params) has no effect — the value is ignored.
Acceleration parameters (acceleration.params)
Set under a dataset's acceleration.params:
| Parameter | Description |
|---|---|
cayenne_tuning | Auto-tuning mode. Accepts auto or adaptive (preview). auto derives the memory-, CPU-, and storage-sensitive knobs statically from the detected environment (cgroup-aware cores and memory, storage class) and the inferred schema (cardinality, row width, primary key) — no feedback loop. adaptive additionally runs a per-table closed-feedback controller that measures the live CDC ingest rate (and delete fraction and arrival burstiness) and the runtime's response (apply latency vs. offered load, read amplification, memory pressure) and adjusts the inline-memtable flush caps, the in-memory CDC tier byte cap, compaction cadence/trigger, and write concurrency over time, within the environment-derived bounds. When unset, the mode defaults to auto; set cayenne_tuning: adaptive explicitly to enable the closed loop. A configured cayenne_goal_* SLO also implies adaptive unless you set cayenne_tuning: auto explicitly. adaptive needs a non-zero cayenne_compaction_background_interval_ms (the controller runs on the background compaction tick); if it is 0, Cayenne falls back to auto. Schema inference (always on) sharpens the adaptive warm-start but is not required — without inferred metadata the controller relearns the observed row width from live ingest. In both modes an explicit per-knob value overrides the derived value; under adaptive an explicitly-set knob is pinned (the loop will not move it). See Self-Tuning. |
cayenne_goal_replication_lag | Goal-driven adaptive tuning (preview): target end-to-end CDC replication lag, as a duration (e.g. 5s). Best set globally under runtime.params; a value here overrides the global setpoint for this dataset. When set, the closed-loop controller converges toward this SLO in small, bounded steps within cayenne_goal_convergence_window. Setting any cayenne_goal_* parameter enables the closed loop unless cayenne_tuning: auto is set explicitly, and requires a non-zero cayenne_compaction_background_interval_ms. See Goal-driven tuning. |
cayenne_goal_freshness | Goal-driven adaptive tuning (preview): target data freshness — the age of the newest queryable data — as a duration (e.g. 30s). Best set globally under runtime.params; a value here overrides the global setpoint for this dataset. |
cayenne_goal_query_latency | Goal-driven adaptive tuning (preview): target p99 query latency on this table, as a duration (e.g. 250ms or 10s). Best set globally under runtime.params; a value here overrides the global setpoint for this dataset. |
cayenne_goal_convergence_window | Goal-driven adaptive tuning (preview): the time budget to converge toward the configured cayenne_goal_* SLOs, as a duration (e.g. 1m). Defaults to 60s. A per-dataset control-cadence knob — it paces how fast the loop chases the goals rather than declaring an outcome, so it is not part of the global SLO surface and has no runtime.params form. |
cayenne_compression_strategy | Compression algorithm for accelerated data. Defaults to btrblocks. Supports btrblocks or zstd. |
cayenne_delta_encoding | Encoding effort applied to delta (incremental) writes such as appends and inline-memtable flushes. Accepts auto (default) or a fixed level 0–10. Higher levels search more encoding schemes for a better compression ratio at the cost of more write-time CPU; auto uses light encoding for small deltas and the full cascade for large writes. Levels 7–10 all apply the full default cascade, so set 7 to opt out of size-gating. Applies at write time only — changing it never re-encodes existing data or forces a table re-create. Invalid values fall back to auto with a warning. |
cayenne_unsupported_type_action | Action when an unsupported data type is encountered. Defaults to error. See Data Type Support. |
cayenne_segment_cache_mb | Size of the in-memory Vortex segment cache in megabytes, caching decompressed data segments for improved query performance. Accepts auto (default) or an explicit MB value. auto scales with machine memory (~1/128 of RAM), but never below 256 MB and never above 1024 MB. |
cayenne_force_view_types | Whether scans emit Arrow view types (Utf8View/BinaryView) instead of native Utf8/Binary. Accepts true or false; defaults to false. View types are not compacted across RepartitionExec, so wide strings fanned out through a partitioned join can inflate query-pool memory reservations — the native types avoid that. Set to true to re-enable view types for a table. Any value other than false (case-insensitive) enables view types. |
cayenne_file_path | Custom path for storing Cayenne data files. Supports local paths or S3 Express One Zone URLs (e.g., s3://bucket--usw2-az1--x-s3/prefix/). |
cayenne_target_file_size_mb | Target size for individual Vortex files in MB. When writes exceed this size, a new Vortex file is created. Accepts auto (default) or an explicit MB value. auto is storage-aware: 256 MB on EBS-class network storage, 64 MB on RAM-backed (tmpfs) mounts, 512 MB on S3 Express (large immutable objects cut object count and per-request cost), and 256 MB on local SSD or unknown storage. Smaller files enable better parallelism and predicate pushdown. |
cayenne_metadata_dir | Custom directory for storing Cayenne metadata (SQLite catalog). Defaults to {spice_data_path}/metadata. |
cayenne_metastore | Metastore backend type. Supports sqlite (default) or turso (requires turso feature flag). |
cayenne_upload_concurrency | Maximum number of concurrent file uploads when writing multiple Vortex files to S3 Express One Zone. Accepts auto (default) or an explicit value; auto uses the available CPU parallelism. The aggregate encode concurrency across all Cayenne tables is separately bounded by a process-global budget sized to the host core count. |
cayenne_write_concurrency | Writer partition override for unsorted ingests, controlling how many Vortex files are encoded in parallel during a write. Accepts auto (default) or an explicit value. auto encodes up to min(4, session target_partitions) files in parallel per write — an intentionally small per-table default (not the host core count), so many independently-writing tables do not oversubscribe CPU under concurrent CDC. An explicitly-set value is capped at the session target_partitions (the host core count); the aggregate encode concurrency across all Cayenne tables is separately bounded by a process-global budget sized to the host core count. Values below 1 are clamped to 1. The sort-and-rewrite compaction path always writes serially regardless of this setting. |
cayenne_deletion_mode | How primary-key deletions are recorded and applied. Accepts auto, key, or position; defaults to auto, which resolves to position (merge-on-read) for most tables, or to key for CDC datasets (refresh_mode: changes) that declare a primary_key. See Deletion Strategies. |
cayenne_pk_conflict_detection | Controls primary-key conflict detection on insert. Accepts auto or none; defaults to auto, which detects existing primary keys and resolves them as merge-on-read upserts. Set to none to skip conflict detection (blind append) for append-only CDC workloads where the source guarantees primary-key uniqueness. |
cayenne_compaction_trigger_files | Minimum number of small Vortex files in the current snapshot before tiered compaction runs. A "small" file is one whose size is below cayenne_target_file_size_mb / 4. Defaults to 4 for refresh_mode: caching / changes, or append with refresh_check_interval ≤ 5m; 8 otherwise. A value of 1 is clamped to a minimum of 2. |
cayenne_compaction_trigger_protected_snapshots | Number of protected snapshots before snapshot-maintenance compaction runs. Separate from cayenne_compaction_trigger_files so small-file tuning does not silently change scan amplification behavior. Defaults to 4 for refresh_mode: caching / changes, or append with refresh_check_interval ≤ 5m; 8 otherwise. A value of 1 is clamped to a minimum of 2. |
cayenne_compaction_trigger_snapshot_age_ms | Maximum age in milliseconds of the oldest protected snapshot before snapshot-maintenance compaction runs. Set to 0 to disable the age trigger. Defaults to 60000 for refresh_mode: caching / changes, or append with refresh_check_interval ≤ 5m; 300000 otherwise. |
cayenne_compaction_max_levels | Maximum number of consecutive compaction passes per trigger. Bounds write amplification when promotion keeps producing new candidates. Defaults to 3. |
cayenne_compaction_max_files_per_pick | Maximum number of eligible file paths retained in one compaction candidate for trigger selection and observability. The current compactor rewrites the whole current snapshot once triggered, so this does not bound rewrite IO or memory. Defaults to 32. |
cayenne_compaction_background_interval_ms | Background compaction interval in milliseconds. The accelerator runs a per-table background task at this interval. Set to 0 to disable the background task — inline compaction on writes still runs. Defaults to 10000 for refresh_mode: caching / changes, or append with refresh_check_interval ≤ 5m; 30000 otherwise. |
cayenne_cdc_durability | Durability mode for the inline CDC write path. Accepts memory (default) or file. memory appends batches to an in-RAM tier and defers the source-slot acknowledgement to a periodic or cap-triggered checkpoint, collapsing per-batch durability cost; on crash the un-checkpointed tail is replayed from the source slot, and because the apply is primary-key-idempotent this remains exactly-once. The in-memory path is eligibility-gated — it applies only to the small-write / CDC profile on non-partitioned tables, and other profiles always use file. file persists each CDC batch durably before advancing the source slot and is the conservative opt-out. |
cayenne_cdc_mem_tier_max_bytes | Per-table RAM-tier byte cap that forces a spill (checkpoint) and source-slot advance, in cayenne_cdc_durability: memory mode only. Auto-derived from host memory (~1/64 of RAM, clamped to 256 MiB–1 GiB; 256 MiB on hosts at or under 16 GiB). A process-global byte budget also bounds aggregate resident memory across all tables; whichever cap is breached first triggers the spill. Set to 0 to disable the per-table cap (the global budget still applies). |
cayenne_cdc_mem_tier_max_age_ms | Maximum wall-clock milliseconds a RAM-tier epoch may age before a forced checkpoint, in cayenne_cdc_durability: memory mode only. Bounds the crash-replay window and the deferred source-slot acknowledgement for tables that never reach a byte threshold. Defaults to 10000 (10 s). Set to 0 to disable the age trigger. |
cayenne_cdc_mem_tier_min_flush_bytes | Minimum resident RAM-tier bytes before the periodic background checkpoint tick durably checkpoints, in cayenne_cdc_durability: memory mode only. Bounds snapshot / delete-file churn — below this size a tick is skipped unless the tier has reached cayenne_cdc_mem_tier_max_age_ms. Query freshness is unaffected (RAM rows are visible immediately); only the deferred slot acknowledgement waits. The write-path byte-cap spill is not gated by this value. Auto-derived as 1/8 of the resolved cayenne_cdc_mem_tier_max_bytes (clamped to 32–128 MiB; 32 MiB on hosts at or under 16 GiB). Set to 0 to flush on every tick. |
cayenne_cdc_mem_tier_checkpoint_interval_ms | Periodic background mem-tier checkpoint interval in milliseconds, in cayenne_cdc_durability: memory mode only. The accelerator spawns a per-table background task that checkpoints the RAM tier every interval, advancing the deferred source-slot acknowledgement on an idle or pure-upsert stream that never trips a write-path cap or event trigger. Defaults to 1000 (1 s). Set to 0 to disable the periodic task. |
sort_columns | Comma-separated list of columns to sort data by on refresh operations. Improves segment pruning for frequently filtered columns. |
unsupported_type_action | Action when encountering unsupported data types. Options: error (default), string, warn, ignore. |
S3 Express One Zone parameters
These are acceleration parameters (set under acceleration.params) used when storing Cayenne data files in S3 Express One Zone:
| Parameter | Description |
|---|---|
cayenne_s3_zone_ids | Comma-separated availability zone IDs (e.g., usw2-az1,usw2-az2). Auto-generates bucket names in format spice-{app}-{dataset}--{zone}--x-s3. |
cayenne_s3_region | AWS region (e.g., us-west-2). Auto-derived from zone ID if not specified. |
cayenne_s3_auth | Authentication method: iam_role (default) or key. |
cayenne_s3_key | AWS access key ID (required when cayenne_s3_auth: key). |
cayenne_s3_secret | AWS secret access key (required when cayenne_s3_auth: key). |
cayenne_s3_session_token | AWS session token (optional, for temporary credentials). |
cayenne_s3_endpoint | Custom S3 endpoint URL (optional, overrides auto-generated endpoint). |
cayenne_s3_client_timeout | Request timeout duration (e.g., 30s, 5m). Defaults to 120s. |
cayenne_s3_unsigned_payload | Use unsigned payload for S3 Express One Zone requests. Defaults to true. |
cayenne_s3_allow_http | Set to true for testing with local S3-compatible storage. Defaults to false. |
Cold object-store tier parameters
These acceleration parameters (set under acceleration.params) configure the optional cold object-store tier. Setting cayenne_datalake_location enables the tier; the rest tune the clustering key, cold file size, the warm→cold promotion trigger, and the cold store's credentials. When cayenne_datalake_location is unset (the default), the cold tier is dormant and behaves byte-identically to a warm-only table.
| Parameter | Description |
|---|---|
cayenne_datalake_location | Object-store URL prefix for the cold tier (the bottom tier of the storage cascade). Must be an s3:// URL (e.g. s3://bucket/prefix) — a general-purpose S3 or S3-compatible bucket, distinct from the warm S3 Express One Zone store. When set, a background promotion stage graduates the warm local-disk tier to read-optimized, Z-order-clustered Vortex files on this store, and queries span the warm and cold tiers with per-tier pushdown. Unset (default) disables the cold tier. Requires key-based deletes (cayenne_deletion_mode auto-resolves to key; an explicit position is rejected at registration) and refresh_mode: changes or append. A primary_key is required to activate the tier — without one the tier registers but stays inactive. v1 constraints: local file:// locations are not supported; partitioned and position-delete tables are not supported. |
cayenne_datalake_clustering_columns | Comma-separated liquid-clustering key columns for cold files (multi-column Z-order), e.g. tenant_id,ts. Clustering tightens each cold file's per-column zone maps so selective queries on any clustering dimension prune at the storage layer. When unset, falls back to cayenne_sort_columns, then the primary key. An entry that does not exist in the schema is ignored with a warning (clustering falls back to cayenne_sort_columns, then the primary key). |
cayenne_datalake_target_file_size_mb | Target size for cold-tier Vortex files in MB. Larger than the warm cayenne_target_file_size_mb because object stores favor fewer, larger objects and cold scans are range reads. Accepts auto or an explicit MB value. Defaults to 512. |
cayenne_datalake_warm_max_bytes | The warm tier graduates to cold once its total Vortex bytes reach this threshold. 0 (default) disables the byte trigger; set alongside cayenne_datalake_warm_max_files to bound warm-tier size. When the tier is enabled and neither trigger is set, Cayenne applies a default byte trigger (16× cayenne_datalake_target_file_size_mb) so promotion is not silently disabled. |
cayenne_datalake_warm_max_files | The warm tier graduates to cold once its Vortex file count reaches this threshold. 0 (default) disables the file-count trigger. |
cayenne_datalake_tiering_check_interval_ms | How often the background loop checks the warm→datalake tiering trigger, in milliseconds. Datalake tiering is not latency-critical, so this is coarser than compaction. Defaults to 60000 (60s). 0 disables the tiering and garbage-collection loop entirely and is rejected at registration when the datalake tier is enabled. |
cayenne_datalake_gc_interval_ms | Physical-GC cadence (and orphan grace) for superseded cold-tier objects: the background sweep runs about this often and deletes an object no longer referenced by the manifest only after it has been observed orphaned for at least one interval. Defaults to 300000 (5m). 0 collapses the grace period to zero (a superseded object could be deleted while a running query still reads it) and is rejected at registration when the cold tier is enabled. |
The cold store is authenticated independently from the warm tier (which uses the cayenne_s3_* parameters) via the following acceleration.params:
| Parameter | Description |
|---|---|
cayenne_datalake_s3_auth | Authentication method for the cold S3 store: iam_role (default, uses environment/SDK credentials) or key. |
cayenne_datalake_s3_key | AWS access key ID for the cold store (required when cayenne_datalake_s3_auth: key). |
cayenne_datalake_s3_secret | AWS secret access key for the cold store (required when cayenne_datalake_s3_auth: key). |
cayenne_datalake_s3_session_token | AWS session token for the cold store (optional, for temporary credentials). |
cayenne_datalake_s3_region | AWS region of the cold bucket. Defaults to the environment region (AWS_REGION / AWS_DEFAULT_REGION), then us-east-1; inert for S3-compatible endpoints. |
cayenne_datalake_s3_endpoint | Custom S3 endpoint URL for the cold store (e.g. an S3-compatible store such as MinIO). http:// endpoints implicitly allow HTTP. |
cayenne_datalake_s3_allow_http | Allow plain-HTTP connections to the cold S3 endpoint. Defaults to false. |
cayenne_datalake_s3_client_timeout | HTTP client timeout for cold-store requests, as a duration (e.g. 2m). Defaults to 2m. |
cayenne_datalake_s3_unsigned_payload | Use unsigned payloads for cold S3 uploads. Defaults to true. |
Runtime parameters (runtime.params)
Set once under the top-level runtime.params and applied to every Cayenne-accelerated dataset in the instance. With the exception of the goal-driven SLO setpoints (cayenne_goal_*) — which set a global default that a dataset can override under its own acceleration.params (except cayenne_goal_qph, which is global-only) — these are not valid under a dataset's acceleration.params:
| Parameter | Description |
|---|---|
cayenne_footer_cache_mb | Size of the engine-wide in-memory Vortex footer cache in megabytes. The footer cache stores Vortex file metadata (schemas, statistics, encoding information) and is shared across all Cayenne datasets. Larger values improve query performance for repeated scans. Optional; when unset, no explicit limit is applied and DataFusion's default file-metadata-cache limit of 50 MB applies (there is no fixed 128 MB default). |
cayenne_filter_propagation | Enables Cayenne's filter-propagation optimizer rules. Accepts enabled or disabled; defaults to disabled. |
cayenne_optimizer_rules | Selects which Cayenne optimizer rules run. Accepts auto (default — enables the recommended set, gated by cayenne_filter_propagation), all, none / disabled, or a comma-separated list of individual rule names. |
cayenne_compaction_memory_fraction | Fraction of the query memory pool carved out for a dedicated Cayenne compaction memory pool. Defaults to 0.2 and is clamped to a supported range. Only applied when at least one Cayenne-accelerated dataset is enabled and dedicated thread pools are not disabled. |
cayenne_sort_merge_min_rows | Advanced anti-join tuning: row-count threshold above which the filter-propagation optimizer switches to a sort-merge strategy. Defaults to an internally tuned value; override only when profiling indicates a need. |
cayenne_sort_merge_memory_pool_fraction | Advanced anti-join tuning: fraction of the memory pool the sort-merge anti-join strategy may use. Defaults to an internally tuned value. |
cayenne_goal_replication_lag | Goal-driven adaptive tuning (preview): global target end-to-end CDC replication lag, as a duration (e.g. 5s), applied to every Cayenne dataset. Override per-dataset under a dataset's acceleration.params. See Goal-driven tuning. |
cayenne_goal_freshness | Goal-driven adaptive tuning (preview): global target data freshness — the age of the newest queryable data — as a duration (e.g. 30s). Override per-dataset under a dataset's acceleration.params. |
cayenne_goal_query_latency | Goal-driven adaptive tuning (preview): global target p99 query latency, as a duration (e.g. 250ms or 10s). Override per-dataset under a dataset's acceleration.params. |
cayenne_goal_qph | Goal-driven adaptive tuning (preview): target query throughput in queries per hour (higher is better), e.g. 5000. Must be a positive number. Global-only — query throughput is measured system-wide (a query spanning multiple datasets, such as a join, is counted once), so it has no per-dataset form; a value set under acceleration.params is ignored. |
cayenne_metastore_cache_mb | SQLite metastore page-cache size in megabytes. Applies to the default sqlite metastore backend (see cayenne_metastore); the turso backend uses MVCC and ignores the cayenne_metastore_* family. Defaults to 256. |
cayenne_metastore_mmap_mb | SQLite metastore memory-mapped I/O size in megabytes. Defaults to 1024 (1 GiB). |
cayenne_metastore_busy_timeout_ms | SQLite metastore busy_timeout in milliseconds — how long a blocked connection waits for a lock before erroring. Defaults to 30000. |
cayenne_metastore_wal_autocheckpoint_pages | SQLite metastore WAL auto-checkpoint threshold in pages. 0 disables the inline auto-checkpoint so the WAL is drained off the hot commit path by a dedicated background checkpoint instead. Defaults to 0. |
cayenne_metastore_wal_truncate_threshold_mb | WAL size in megabytes above which the background checkpoint escalates to a TRUNCATE checkpoint to reclaim file space. Defaults to 160. |
cayenne_metastore_auto_vacuum | SQLite metastore auto_vacuum mode: none, incremental, or full. Takes effect only on a fresh database (an existing database needs a full VACUUM to change it). Defaults to none. |
runtime:
params:
# Engine-global Cayenne tuning, shared by every Cayenne-accelerated dataset
cayenne_footer_cache_mb: 512
cayenne_filter_propagation: enabled
datasets:
- from: s3://analytics-bucket/events/
name: events
acceleration:
engine: cayenne
mode: file
params:
# Per-dataset Cayenne tuning
cayenne_segment_cache_mb: 1024
Performance Tuning
Spice Cayenne is self-tuning by default and rarely needs manual tuning. For the full tuning reference — self-tuning and goal-driven SLOs, cache sizing, compression strategy, and file-size tuning — see the dedicated Performance Tuning page.
Features
DataFusion Query-Native Execution
Spice Cayenne is DataFusion query-native, meaning all query execution uses Apache DataFusion and adheres to the runtime.query.memory_limit setting. This provides:
- Vectorized execution: Multi-threaded, SIMD-optimized query processing
- Automatic memory management: Query memory is tracked and spilled to disk when limits are exceeded
- Dynamic filter pushdown: Filters from TopK, Join, and Aggregate operators push down to file scans
DataFusion's GreedyMemoryPool allows memory reservations on a first-come, first-served basis, improving throughput for high-concurrency queries with many partitions.
High-Performance Columnar Storage
Spice Cayenne uses Vortex's advanced columnar format, which provides:
- Efficient Compression: Cascading compression with nested encoding schemes including RLE, dictionary encoding, FastLanes, FSST, and ALP
- Rich Statistics: Lazy-loaded summary statistics for query optimization
- Extensible Encodings: Pluggable physical layouts optimized for different data patterns
- Wide Table Support: Efficient handling of tables with many columns through zero-copy metadata access
Point Lookups and Random Access
Vortex delivers 100x faster random access reads compared to Apache Parquet through several architectural features:
Segment Statistics (Zone-Map Equivalent):
Vortex's ChunkedLayout maintains per-segment statistics for each column, enabling segment pruning during query execution. Statistics include:
| Statistic | Description | Use Case |
|---|---|---|
min | Minimum value in segment | Range predicate pruning |
max | Maximum value in segment | Range predicate pruning |
null_count | Count of null values | IS NULL/IS NOT NULL optimization |
is_sorted | Whether segment is sorted | Binary search for point lookups |
is_constant | Whether all values are identical | Immediate value return |
When a query includes a WHERE clause, Spice Cayenne evaluates whether each segment could contain matching rows. Segments that cannot match based on min/max statistics are skipped entirely, similar to DuckDB's zone-maps without requiring explicit index creation.
Example - Segment Pruning:
For a table with segments containing timestamp ranges [2024-01-01, 2024-01-15], [2024-01-16, 2024-01-31], [2024-02-01, 2024-02-15], a query:
SELECT * FROM events WHERE timestamp > '2024-01-20';
Prunes the first segment (max < 2024-01-20) and reads only the second and third segments.
Fast Random Access Encodings:
Vortex encodings support direct random access to compressed data:
- FSST (Fast Static Symbol Table): String compression with O(1) random access
- FastLanes: High-performance integer encoding with vectorized decoding
- ALP: Adaptive lossless floating-point compression with random access
Compute Push-Down:
Vortex supports executing filter and compute operations directly on compressed data, avoiding full decompression for predicate evaluation. This compute push-down reduces CPU and memory overhead by processing data in its compressed form:
| Encoding | Data Type | Operations |
|---|---|---|
| FSST | Strings | Equality, prefix matching on compressed symbols |
| FastLanes | Integers | SIMD-accelerated comparison on bit-packed data |
| ALP | Floats | Range comparisons with minimal decompression |
| Dictionary | Any | Lookup predicates evaluated on dictionary indices |
| RLE | Any | Constant runs evaluated once per run |
Array-level statistics (is_sorted, is_constant, min, max) enable additional optimizations beyond filtering. For example, is_sorted enables binary search for point lookups, and is_constant returns values immediately without scanning.
Performance Characteristics:
For point lookups and selective queries, Spice Cayenne with Vortex often matches or exceeds the performance of traditional B-tree indexes while consuming no additional memory for index structures. Performance scales with:
- Data sorting (sorted columns benefit most from segment pruning)
- Segment cache hit rate (hot data patterns)
- Compression encoding match to data characteristics
Change Data Capture (refresh_mode: changes)
Spice Cayenne is the recommended accelerator for Change Data Capture (CDC). A dataset configured with refresh_mode: changes is bootstrapped from a source snapshot and then kept continuously in sync by applying the source's row-level change stream — inserts, updates, and deletes — so the acceleration reflects the current state of the source row-for-row.
CDC into Cayenne is available for every Spice CDC connector:
- PostgreSQL Logical Replication
- MySQL Binlog Replication
- MongoDB Change Streams
- DynamoDB Streams
- Debezium (over Kafka)
See Change Data Capture for source-side setup and the Changes refresh mode reference for the acceleration-side configuration.
datasets:
- from: postgres:public.orders
name: orders
acceleration:
engine: cayenne
mode: file
refresh_mode: changes
Cayenne is not the only engine that can apply a change stream — arrow, duckdb, and sqlite are also valid changes sinks — but Cayenne adds CDC-specific capabilities built for large-scale, continuously-updated datasets:
- Incrementally maintained aggregate views (IVM). Aggregate views declared with
maintained_aggregatesare updated in place as each change event is applied, rather than recomputed, soGROUP BYrollups stay fresh at CDC speed. See Maintained Aggregates. - Key-based incremental deletes. With a primary key,
cayenne_deletion_mode: autoresolves to key-based deletion vectors so sourceDELETEandUPDATEevents apply efficiently. See Deletion Vectors. - In-memory CDC tier. Change events can be staged through an in-memory tier (
cayenne_cdc_durabilityand thecayenne_cdc_mem_tier_*parameters) for low apply latency, with exactly-once semantics via primary-key-idempotent replay. The deployment guide documents the CDC apply metrics for monitoring lag and throughput. - Replication-lag and freshness SLOs. The adaptive self-tuner can target an end-to-end replication-lag or data-freshness goal (
cayenne_goal_replication_lag,cayenne_goal_freshness) and adjust its apply behavior to meet it. See Goal-driven tuning.
CDC Requirements
- A primary key is required. In
changesmode Cayenne always applies an inferred or declared primary key and routes source updates through an upsert. Declareprimary_keyon the dataset (and, where the connector requires it,on_conflict: upsert); the per-connector CDC pages document the exact requirement. - File or memory mode. Durable resume across restarts requires
mode: file.mode: memoryis supported for ephemeral, in-RAM CDC where the accelerator is rebuilt from the source on restart.
Maintained Aggregates
Spice Cayenne can incrementally maintain aggregate views over a CDC-accelerated dataset so that GROUP BY aggregate queries are answered from continuously-updated summary state instead of re-scanning the full table. As change events are applied (refresh_mode: changes), each maintained view is updated with the incoming deltas; a matching query is then rewritten by the physical optimizer to read the maintained state directly. When a query does not match a declared view — or the view is not currently fresh — Cayenne transparently falls back to a full scan, so results are always correct.
Maintained aggregates are declared per dataset under acceleration.maintained_aggregates:
datasets:
- from: postgres:orders
name: orders
acceleration:
enabled: true
engine: cayenne
refresh_mode: changes
primary_key: id
maintained_aggregates:
- group_by: [customer_id]
aggregates:
- function: count
- function: sum
column: amount
- function: avg
column: amount
- function: min
column: amount
- function: max
column: amount
Each entry declares one maintained view:
| Field | Required | Description |
|---|---|---|
group_by | Optional | Columns used as the GROUP BY key, in query output order. Omit for a single-group (grand total) view. |
aggregates | Required | Aggregate expressions maintained for each group, in query output order. |
filter_sql | Optional | A SQL row predicate (a WHERE expression over the dataset's columns, e.g. ol_delivery_d > '2007-01-02') restricting which rows contribute to the view. |
Each item in aggregates has:
| Field | Required | Description |
|---|---|---|
function | Required | One of count, sum, avg, min, or max. |
column | Conditional | The column to aggregate. Omit for count (COUNT(*)); required for sum, avg, min, and max. |
Supported input column types by function:
count— any column (orCOUNT(*)whencolumnis omitted).sumandavg— signed integers (Int8–Int64), unsigned integers (UInt8–UInt64), and floats (Float32/Float64).sumwidens toBIGINT/Float64;avgalways returnsFloat64.minandmax— signed/unsigned integers,Date32/Date64,Timestamp, andDecimal128, preserving the input type (MIN(Int32) -> Int32). Floatmin/maxis not yet supported.
Query matching
A query is served from a maintained view only when it matches the view exactly:
- The query's
GROUP BYkeys match the view'sgroup_by, in order. - The query's
WHEREpredicate matches the view'sfilter_sqlexactly — an unfiltered view (nofilter_sql) answers only unfiltered queries, and a filtered view answers only a query carrying the identical predicate. A view whosefilter_sqlmirrors a common dashboard filter lets that filtered analytical query be served incrementally instead of by a full re-scan.
Any query that does not match a declared view (or that reaches the view while it is stale) falls back to the base-table scan — correct, but not accelerated.
Constraints
- Maintained aggregates are a Spice Cayenne feature designed for CDC-accelerated datasets (
refresh_mode: changes). minandmaxare retraction-hard: they require aprimary_keyon the acceleration so thatUPDATEandDELETEchanges can retract a prior extremum. Setacceleration.primary_key, enable extended schema inference for a source primary key, or omitmin/max.count,sum, andavgdo not require a primary key.- Maintained aggregates are not supported on partitioned tables (
partition_by).
Retaining specs without maintaining them
To keep a view's declaration in configuration without materializing or maintaining it, use the policy form with mode: disabled:
maintained_aggregates:
mode: disabled
views:
- group_by: [customer_id]
aggregates:
- function: sum
column: amount
When any view is declared with the list form above, maintenance is enabled by default; the policy form's mode: enabled is equivalent.
Deletion Vectors
Spice Cayenne implements efficient deletes without rewriting data files using deletion vectors. Deletion vectors track which rows have been logically deleted, and the information is applied transparently during query execution.
Deletion Strategies
How deletions are recorded and applied is controlled by the cayenne_deletion_mode parameter:
| Mode | How deletes are applied |
|---|---|
auto (default) | Resolves to position (merge-on-read) for most tables. For CDC datasets (refresh_mode: changes) that declare a primary_key, auto resolves to key instead, so deletes compact concurrently with the continuous writer. |
position | Per-file row-position RoaringBitmaps are pushed into the Vortex scan, skipping deleted rows at the storage layer with no per-row CPU cost. |
key | Deletes are applied above the Vortex scan via a per-row probe on the byte representation of the primary key columns. The explicit opt-out from merge-on-read for primary-key tables. |
datasets:
- from: s3://bucket/events/
name: events
acceleration:
engine: cayenne
mode: file
primary_key: event_id
params:
cayenne_deletion_mode: auto # default; set to `key` to opt out of merge-on-read
Under position mode (the auto resolution for all tables except CDC datasets with a primary key):
- Tables without a primary key record deletions by row position. Cayenne uses
RoaringBitmapfor memory-efficient storage of deleted row IDs, providing 50-90% memory savings compared toHashSetfor sparse deletions. - Tables with a primary key capture row positions via a
row_idx()read-back after each write, with a key-based fallback for any row whose position is not yet known. Pushing the deletes into the scan eliminates the per-rowRowConverterdeletion tax above it.
Key-based deletion (cayenne_deletion_mode: key) uses the byte representation of primary key columns and applies deletes above the scan. This approach is position-independent and survives data reorganization.
Orphaned deletion-vector cleanup
On a primary-key upsert table, a deletion vector becomes orphaned once time-based retention empties the snapshot(s) it shadowed — the surviving-sequence floor rises above the DV's delete sequence, so the DV is a query-time no-op that still occupies disk and the in-memory deletion cache. Cayenne runs a background sweep that reclaims these orphaned .arrow files and their catalog rows.
The sweep is always on and requires no configuration:
- Fixed per-table threshold — the sweep runs per-table once at least 20 orphaned DVs have accumulated. This threshold is a fixed internal constant, not a tunable parameter.
- Retention-only — a DV is orphaned only after retention (
retention_period+time_column) empties the snapshots it shadowed. Without a retention policy nothing is ever orphaned and the sweep is a no-op, at zero ingest cost. - No correctness impact — orphaned DVs are already query-time no-ops; the benefit is reclaimed disk plus a smaller in-memory deletion cache and less file I/O at restart.
- Off the write path — the sweep is lock-free and throttled, and runs on the compaction runtime; it never extends the write-lock window.
The sweep bounds only the orphaned tail. The live (not-yet-orphaned) DV set is bounded separately by compaction.
Primary Key Optimization
For tables with a single-column Int64 primary key, Cayenne uses an optimized direct lookup strategy that avoids serialization overhead:
datasets:
- from: s3://bucket/events/
name: events
acceleration:
engine: cayenne
mode: file
primary_key: event_id # Int64 column - uses optimized deletion
Upsert Support
When on_conflict is configured, Cayenne supports upsert semantics using sequence numbers (Iceberg-style ordering):
datasets:
- from: kafka:events
name: events
acceleration:
engine: cayenne
mode: file
primary_key: id
on_conflict:
id: upsert
When a primary key is deleted and then re-inserted:
- The new insert gets a higher sequence number than the delete
- During scan, the delete doesn't apply to data with higher sequence numbers
- The new data is visible without requiring separate tracking of "undeleted" records
AWS S3 Express One Zone Storage
Spice Cayenne supports storing data files in AWS S3 Express One Zone for single-digit millisecond latency, ideal for latency-sensitive query workloads that require persistence. Metadata remains on local disk for fast catalog operations while data files are stored in S3 Express One Zone.
Why S3 Express One Zone?
S3 Express One Zone directory buckets provide:
- Single-digit millisecond latency: 10x faster than S3 Standard for first-byte latency
- High request throughput: Up to 10x higher request rates than S3 Standard
- Cost efficiency: Lower per-request costs for high-frequency access patterns
- Durability: Same 99.999999999% (11 9s) durability as S3 Standard
S3 Express Examples
Example 1 - Explicit bucket:
datasets:
- from: s3://source-bucket/events/
name: analytics_events
acceleration:
engine: cayenne
enabled: true
mode: file
params:
# Store data in S3 Express One Zone bucket
cayenne_file_path: s3://my-bucket--usw2-az1--x-s3/cayenne/
cayenne_s3_region: us-west-2
Example 2 - Auto-generated bucket with IAM role:
datasets:
- from: postgresql://db/events
name: fast_events
acceleration:
engine: cayenne
enabled: true
mode: file
params:
# Auto-generates bucket: spice-{spicepod-name}-fast_events--usw2-az1--x-s3
cayenne_s3_zone_ids: usw2-az1
Example 3 - Explicit credentials:
datasets:
- from: kafka:events
name: realtime
acceleration:
engine: cayenne
enabled: true
mode: file
params:
cayenne_s3_zone_ids: use1-az4
cayenne_s3_region: us-east-1
cayenne_s3_auth: key
cayenne_s3_key: ${secrets:AWS_ACCESS_KEY_ID}
cayenne_s3_secret: ${secrets:AWS_SECRET_ACCESS_KEY}
Bucket Naming Conventions
S3 Express One Zone buckets use a specific naming format:
- Format:
{base-name}--{zone-id}--x-s3 - Zone ID format:
{region-code}-az{number}(e.g.,usw2-az1,use1-az4) - Auto-generated names:
spice-{app-name}-{dataset-name}--{zone-id}--x-s3
The zone ID is automatically extracted from the bucket name to configure the correct endpoint.
Supported AWS Regions
S3 Express One Zone is available in select regions. Spice automatically derives the region from zone IDs:
| Zone ID Prefix | Region |
|---|---|
use1 | us-east-1 |
use2 | us-east-2 |
usw1 | us-west-1 |
usw2 | us-west-2 |
euw1 | eu-west-1 |
euw2 | eu-west-2 |
euw3 | eu-west-3 |
euc1 | eu-central-1 |
eun1 | eu-north-1 |
eus1 | eu-south-1 |
apne1 | ap-northeast-1 |
apne2 | ap-northeast-2 |
apse1 | ap-southeast-1 |
apse2 | ap-southeast-2 |
aps1 | ap-south-1 |
sae1 | sa-east-1 |
cac1 | ca-central-1 |
afs1 | af-south-1 |
mes1 | me-south-1 |
See AWS documentation for the complete list of S3 Express One Zone availability zones.
Important Considerations
- Standard S3 not supported: Cayenne currently only supports S3 Express One Zone, not standard S3 buckets.
- Same-AZ optimization: S3 Express One Zone is optimized for same-availability-zone access. For external access, Cayenne uses extended timeouts (a 2-minute per-request timeout by default, configurable via
cayenne_s3_client_timeout) and retries. - Bucket auto-creation: When using
cayenne_s3_zone_ids, Spice automatically creates the S3 Express directory bucket if it doesn't exist (requires appropriate IAM permissions). - Metadata locality: Cayenne metadata (SQLite catalog) remains on local disk. Only data files are stored in S3 Express.
Cold Object-Store Tier
Cayenne can cascade data across three storage tiers — an in-RAM mem-tier, a local-disk warm tier, and an object-store cold tier — with each row living in exactly one tier. The cold tier is optional and disabled by default; it is enabled by setting cayenne_datalake_location. When unset, a table is warm-only and behaves byte-identically to before.
The cold tier lets a table grow beyond local NVMe capacity while keeping recent, hot data on fast local storage and graduating older data to cheaper, durable object storage — without sacrificing pushdown on the cold data.
How it works
- Promotion (write path). A dedicated background worker graduates the warm tier once the size or file-count threshold (
cayenne_datalake_warm_max_bytes/cayenne_datalake_warm_max_files) is crossed, evaluated everycayenne_datalake_tiering_check_interval_ms. Promotion is incremental carry-forward: rather than re-materializing the whole table each cycle, it classifies the existing cold manifest into dirty files that may host a tombstoned key — using per-PK-column min/max rectangles from each file's persisted statistics, refined by a per-file PK bloom filter, and conservative in the safe direction (a false positive costs an extra rewrite; a missed tombstone is impossible) — and clean files that are provably untouched. Only the warm delta plus the dirty files are re-read (all deletes applied, one version per key), Z-order clustered for tight multi-column zone maps, and written as read-optimized Vortex at the largercayenne_datalake_target_file_size_mbunder a per-promotion prefix; clean files are carried forward by manifest reference and never re-read. The new files are atomically registered while the promoted warm files are cleared in a single transaction, so promotion cost tracks the changed data, not total table size. - Cross-tier scan (read path). Queries span all tiers and push filters, projection, and limits down to each. Cold files are pruned from statistics held in the metastore, so pruning requires no object-store round-trip on the query path. Each cold file's PK bloom lets an upsert's keyset rebuild answer cold-tier key existence without scanning the object store. A
DELETEafter promotion correctly hides a cold-resident row. - Physical GC. A periodic mark-and-sweep, rooted at the manifest, reclaims cold objects orphaned by carry-forward rewrites. It runs every
cayenne_datalake_gc_interval_ms(default 5m), which doubles as the orphan grace period: an object no longer referenced by the manifest is deleted only after it has been observed orphaned for at least one interval. - Clustering. Cold files are clustered by
cayenne_datalake_clustering_columns(multi-column Z-order / Morton order), falling back tocayenne_sort_columnsand then the primary key. Clustering on more than one dimension prunes far better than a single-column sort for selective queries on any clustering column.
Requirements and v1 constraints
- Key-based deletes required. The cold tier requires
cayenne_deletion_mode: key. Whencayenne_deletion_modeis unset (orauto), Cayenne auto-resolves it tokeyfor a datalake-enabled table. An explicitcayenne_deletion_mode: positionconflicts with the cold tier and is rejected at registration — position deletes are file-path scoped and cannot survive the warm→cold rewrite. Setcayenne_deletion_mode: key(or remove it), or removecayenne_datalake_location. - Primary key required to activate. Promotion classifies and rewrites cold files by primary key, so a table that sets
cayenne_datalake_locationbut declares noprimary_keyregisters successfully with the datalake tier inactive — data is never promoted and remains in the warm tier (Cayenne logs a loud warning). Add aprimary_keyto activate the tier, or removecayenne_datalake_location. Leaving PK-less tables inactive (rather than failing registration) lets a fleet-wide datalake location coexist with datasets that have no primary key. - Non-zero background intervals. When the cold tier is enabled,
cayenne_datalake_tiering_check_interval_ms: 0(which would disable the datalake tiering and garbage-collection loop) andcayenne_datalake_gc_interval_ms: 0(which would collapse the GC grace period, risking deletion of an object a running query still reads) are rejected at registration. Leave them at their defaults or set a positive value. - S3-only location. The cold location must be an
s3://URL — a general-purpose S3 or S3-compatible bucket (for example MinIO viacayenne_datalake_s3_endpoint), authenticated independently through thecayenne_datalake_s3_*parameters. It is a separate store from the warm S3 Express One Zone tier and does not need to share its bucket. Localfile://cold locations are not supported in v1. - Continuous refresh only. The cold tier requires
refresh_mode: changesorrefresh_mode: append; afullrefresh re-materializes the whole table each cycle and is rejected. - Unsupported in v1: partitioned tables and position-delete tables.
datasets:
- from: postgres:public.events
name: events
acceleration:
engine: cayenne
mode: file
refresh_mode: changes
primary_key: event_id
params:
# Enable the cold object-store tier (general-purpose S3, not S3 Express)
cayenne_datalake_location: s3://my-cold-bucket/events/
cayenne_datalake_s3_region: us-west-2
cayenne_datalake_clustering_columns: tenant_id,created_at
# Graduate the warm tier to cold once it reaches 8 GiB
cayenne_datalake_warm_max_bytes: 8589934592
Data Type Support
Cayenne (via Vortex) supports most Arrow data types with the following considerations:
Fully Supported Types
- All integer types (
Int8,Int16,Int32,Int64,UInt*) - Floating point (
Float32,Float64) - Boolean
- Utf8 and LargeUtf8 strings
- Binary and LargeBinary
- Timestamps (normalized to Microsecond precision)
- Date32 and Date64
- Lists and FixedSizeLists
- Maps
- Structs
Automatically Converted Types
| Original Type | Converted To | Notes |
|---|---|---|
Float16 | Float32 | Automatic conversion for Vortex compatibility |
Timestamp(Nanosecond/...) | Timestamp(Microsecond) | Precision normalized |
Unsupported Types
The following types require the unsupported_type_action parameter:
IntervaltypesDurationtypesFixedSizeBinary
unsupported_type_action options:
| Value | Behavior |
|---|---|
error | Fail with error (default) |
string | Convert to Utf8 string |
warn | Include as-is with warning (may fail on insert) |
ignore | Skip the column entirely |
acceleration:
engine: cayenne
mode: file
params:
unsupported_type_action: string # Convert unsupported types to strings
Resource Considerations
Resource requirements for Spice Cayenne depend on dataset size, query patterns, and cache configuration.
Memory
Spice Cayenne manages memory efficiently through columnar storage and selective caching. Memory allocation should account for:
| Component | Default | Notes |
|---|---|---|
| Runtime overhead | ~500 MB | Fixed baseline for the Spice runtime |
| Footer cache | 50 MB | Unset by default (DataFusion file-metadata-cache default); increase for datasets with many files (1-10 KB per file) |
| Segment cache | 256 MB | Increase based on hot data volume |
| Query execution | Variable | Depends on query complexity and concurrency |
Example - Memory-constrained environment:
runtime:
params:
cayenne_footer_cache_mb: 64
datasets:
- from: s3://my-bucket/data/
name: constrained_data
acceleration:
engine: cayenne
mode: file
params:
cayenne_segment_cache_mb: 128
Storage
Spice Cayenne stores data in a columnar format optimized for analytical queries. Storage requirements include:
- Acceleration data: Compressed Vortex files (typically 30-50% of raw data size with btrblocks)
- Metadata: SQLite database for catalog and statistics (~10 MB per 1000 files)
- Temporary files: Query spill files during complex operations
CPU
Query performance scales with available CPU cores. Vortex's columnar format supports parallel decompression and scanning across multiple threads. Allocate sufficient CPU for:
- Query execution parallelism
- Data refresh and compression operations
- Concurrent query workloads
Transactions
Cayenne supports serializable, gated transactions on accelerator-only Cayenne tables. A client submits a single BEGIN … COMMIT SQL body — over the HTTP /v1/sql endpoint or FlightSQL — and every statement in the body commits atomically, or not at all:
BEGIN;
SELECT assert((SELECT balance FROM accounts WHERE id = 1) >= 100); -- optional gate
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
COMMIT;
How it works:
- Detection is automatic. A multi-statement body whose first statement is
BEGIN(orSTART TRANSACTION) and whose last statement isCOMMITis executed as a transaction — there is no configuration flag to enable it. Every statement runs through the standard query path, so authorization, column masking, logging, and tracing apply to each. - Atomicity and isolation. Writes are staged off-lock and published together in a single metastore transaction at
COMMIT. Each participant table's version is captured atBEGINand re-validated atCOMMITusing per-key optimistic concurrency control (OCC). If a participant changed since the transaction started,COMMITfails with a retryable conflict (HTTP409on/v1/sql) — re-run the transaction against the latest committed state. Any statement error (including a failed gate) rolls back every staged write. - Preconditions with
assert(). Theassert(<boolean expression>)function evaluates its argument at execution time. If the expression isfalseorNULL, the transaction aborts withassertion failed: gate expression was false or NULL. Use it to enforce invariants (for example, a sufficient balance) as part of the transaction. Comparison gates such as… >= capare NULL-safe. - Return value. On success,
/v1/sqlreturns the final statement's result (for the canonical gate-plus-write shape, the last write's row-count summary), orCOMMITwhen the body produces no rows.
Durable federated write-back: A Cayenne dataset configured with write_mode: write_back, on_conflict, and refresh_mode: changes (CDC) also participates in transactions. Its committed writes are staged to the accelerator and then reconciled asynchronously back to the federated source by a per-table write-back worker. write_mode: write_back requires replication.enabled: true as an explicit opt-in to asynchronous source durability.
Requirements and v1 limitations:
- Write targets must be accelerator-only, non-partitioned Cayenne datasets (or durable write-back Cayenne datasets, as described above). Other dataset modes route writes to the federated source — where the gate cannot govern them — and are rejected.
- Only
INSERTandUPDATEwrites are supported inside a transaction.DELETEandMERGEare rejected. - At most one write per table per transaction. Multiple tables may be written in the same transaction and are committed atomically together.
- Reading a Cayenne table that is not a registered participant (for example, a partitioned table) fails the transaction closed.
- Nullability-predicate gates (
IS NOT NULL,IS NULL,COALESCE) are not yet reliable — prefer comparison gates. - A gated write whose superseded row is still in the in-memory/inline tier (recently CDC-streamed rows) is rejected; file-backed rows are supported.
Limitations
Consider the following limitations when using Spice Cayenne acceleration:
- Memory Mode Constraints:
mode: memory(fully in-RAM, ephemeral) is supported alongsidemode: file, but it does not persist any data (the dataset reloads from its source on restart), does not support partitioned tables (partition_by), and enforces a hard per-table RAM bound instead of spilling to disk — a breach returns an error rather than growing without limit. Usemode: filewhen persistence across restarts is required. - S3 Express Only: Standard S3 buckets are not supported for remote storage. Only S3 Express One Zone directory buckets are supported.
- Unsupported Data Types:
Interval,Duration, andFixedSizeBinarytypes requireunsupported_type_actionconfiguration. - No Traditional Indexes: Spice Cayenne does not support explicit index creation via the
indexesconfiguration. Vortex's segment statistics and fast random access encodings provide equivalent or better performance for most point lookup workloads. - No MVCC: Multi-version concurrency control is not yet implemented. Snapshots and time-travel queries are planned for future releases.
- Transaction Constraints: Transactions support gated
INSERT/UPDATEwrites on accelerator-only, non-partitioned Cayenne tables only (noDELETE/MERGE, one write per table). See Transactions for the full list.
Example Spicepod
Complete example configuration using Spice Cayenne with performance tuning:
version: v1
kind: Spicepod
name: cayenne-example
runtime:
query:
memory_limit: 4GiB
temp_directory: /tmp/spice
params:
# Engine-global Cayenne runtime tuning (shared by all Cayenne datasets)
cayenne_footer_cache_mb: 256
datasets:
# Local file storage example with upsert
- from: s3://source-bucket/analytics/
name: analytics_data
params:
file_format: parquet
time_column: created_at
acceleration:
engine: cayenne
enabled: true
mode: file
primary_key: id
on_conflict:
id: upsert
refresh_mode: append
refresh_check_interval: 1h
params:
cayenne_compression_strategy: btrblocks
cayenne_segment_cache_mb: 512
cayenne_target_file_size_mb: 64
sort_columns: created_at,id
retention_sql: DELETE FROM analytics_data WHERE created_at < NOW() - INTERVAL '30 days'
# S3 Express One Zone storage example
- from: kafka:realtime-events
name: realtime_events
acceleration:
engine: cayenne
enabled: true
mode: file
primary_key: event_id
refresh_mode: append
params:
# S3 Express One Zone for low-latency persistence
cayenne_s3_zone_ids: usw2-az1
cayenne_s3_region: us-west-2
cayenne_compression_strategy: zstd # Fast writes for streaming
cayenne_target_file_size_mb: 32 # Smaller files for faster ingestion
Cookbook
- A cookbook recipe to configure Cayenne as a data accelerator in Spice. Cayenne Data Accelerator
Related Documentation
Spice Documentation:
- Performance Tuning - Comprehensive performance optimization guide
- Managing Memory Usage - Memory configuration reference
- Data Acceleration - Data acceleration overview
External References:
- Apache DataFusion - Query execution engine
- DataFusion Configuration - DataFusion settings and tuning
- Vortex Project - Columnar file format
- Vortex Benchmarks - Performance benchmarks
- FSST Paper - Fast Static Symbol Table compression
- FastLanes Paper - High-performance integer encoding
- ALP Paper - Adaptive floating-point compression
- BtrBlocks Paper - Compression algorithm
- AWS S3 Express One Zone - Low-latency object storage
