Announcing the release of Spice v1.11.0-rc.2! ⭐
v1.11.0-rc.2 is the second release candidate for advanced test of v1.11. It brings Spice Cayenne to Beta status with acceleration snapshots support, a new ScyllaDB Data Connector, upgrades to DataFusion v51, Arrow 57.2, and iceberg-rust v0.8.0. It includes significant improvements to distributed query, caching, and observability.
Spice Cayenne has been promoted to Beta status with acceleration snapshots support and numerous stability improvements.
Improved Reliability:
- Fixed timezone database issues in Docker images that caused acceleration panics
- Resolved
FuturesUnordered reentrant drop crashes
- Fixed memory growth issues related to Vortex metrics allocation
- Metadata catalog now properly respects
cayenne_file_path location
- Added warnings for unparseable configuration values
Example configuration with snapshots:
datasets:
- from: s3://my-bucket/data.parquet
name: my_dataset
acceleration:
enabled: true
engine: cayenne
mode: file
Apache DataFusion has been upgraded to v51, bringing significant performance improvements, new SQL features, and enhanced observability.
Performance Improvements:
- Faster
CASE Expression Evaluation: Expressions now short-circuit earlier, reuse partial results, and avoid unnecessary scattering, speeding up common ETL patterns
- Better Defaults for Remote Parquet Reads: DataFusion now fetches the last 512KB of Parquet files by default, typically avoiding 2 I/O requests per file
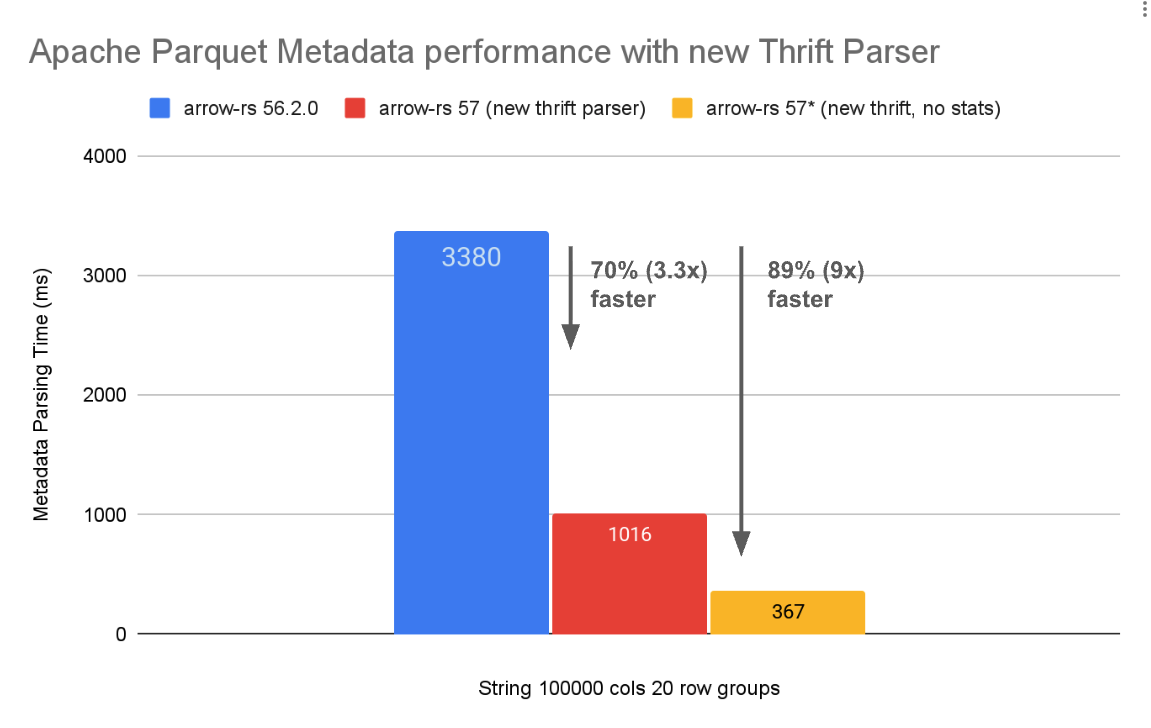
- Faster Parquet Metadata Parsing: Leverages Arrow 57's new thrift metadata parser for up to 4x faster metadata parsing
New SQL Features:
- SQL Pipe Operators: Support for
|> syntax for inline transforms
DESCRIBE <query>: Returns the schema of any query without executing it- Named Arguments in SQL Functions: PostgreSQL-style
param => value syntax for scalar, aggregate, and window functions
- Decimal32/Decimal64 Support: New Arrow types supported including aggregations like
SUM, AVG, and MIN/MAX
Example pipe operator:
SELECT * FROM t
|> WHERE a > 10
|> ORDER BY b
|> LIMIT 5;
Improved Observability:
- Improved
EXPLAIN ANALYZE Metrics: New metrics including output_bytes, selectivity for filters, reduction_factor for aggregates, and detailed timing breakdowns
Spice has been upgraded to Apache Arrow Rust 57.2.0, bringing major performance improvements and new capabilities.
Key Features:
- 4x Faster Parquet Metadata Parsing: A rewritten thrift metadata parser delivers up to 4x faster metadata parsing, especially beneficial for low-latency use cases and files with large amounts of metadata
- Parquet Variant Support: Experimental support for reading and writing the new Parquet Variant type for semi-structured data, including shredded variant values
- Parquet Geometry Support: Read and write support for Parquet Geometry types (
GEOMETRY and GEOGRAPHY) with GeospatialStatistics
- New
arrow-avro Crate: Efficient conversion between Apache Avro and Arrow RecordBatches with projection pushdown and vectorized execution support
Spice has been upgraded to iceberg-rust v0.8.0, bringing improved Iceberg table support.
Key Features:
- V3 Metadata Support: Full support for Iceberg V3 table metadata format
INSERT INTO Partitioned Tables: DataFusion integration now supports inserting data into partitioned Iceberg tables- Improved Delete File Handling: Better support for position and equality delete files, including shared delete file loading and caching
- SQL Catalog Updates: Implement
update_table and register_table for SQL catalog
- S3 Tables Catalog: Implement
update_table for S3 Tables catalog
- Enhanced Arrow Integration: Convert Arrow schema to Iceberg schema with auto-assigned field IDs,
_file column support, and Date32 type support
Acceleration snapshots enable point-in-time recovery and data versioning for accelerated datasets. Snapshots capture the state of accelerated data at specific points, allowing for fast bootstrap recovery and rollback capabilities.
Key Feature Improvements in v1.11:
- Flexible Triggers: Configure when snapshots are created based on time intervals or stream batch counts
- Automatic Compaction: Reduce storage overhead by compacting older snapshots (DuckDB only)
- Bootstrap Integration: Snapshots can reset cache expiry on load for seamless recovery (DuckDB with Caching refresh mode)
- Smart Creation Policies: Only create snapshots when data has actually changed
Example configuration:
datasets:
- from: s3://my-bucket/data.parquet
name: my_dataset
acceleration:
enabled: true
engine: cayenne
mode: file
snapshots: enabled
snapshots_trigger: time_interval
snapshots_trigger_threshold: 1h
snapshots_creation_policy: on_changed
Snapshots API and CLI: New API endpoints and CLI commands for managing snapshots programmatically. List, create, and restore snapshots directly from the command line or via HTTP.
For more details, refer to the Acceleration Snapshots Documentation.
A new data connector for ScyllaDB, the high-performance NoSQL database compatible with Apache Cassandra. Query ScyllaDB tables directly or accelerate them for faster analytics.
Example configuration:
datasets:
- from: scylladb:my_keyspace.my_table
name: scylla_data
acceleration:
enabled: true
engine: duckdb
For more details, refer to the ScyllaDB Data Connector Documentation.
mTLS Verification: Cluster communication between scheduler and executors now supports mutual TLS verification for enhanced security.
Credential Propagation: Azure and GCS credentials are now automatically propagated to executors in cluster mode, enabling access to cloud storage across the distributed query cluster.
Improved Resilience:
- Exponential backoff for scheduler disconnection recovery
- Increased gRPC message size limit from 16MB to 100MB for large query plans
- HTTP health endpoint for cluster executors
- Automatic executor role inference when
--scheduler-address is provided
For more details, refer to the Distributed Query Documentation.
The Caching Acceleration Mode introduced in v1.10.0 has received significant performance optimizations and reliability fixes in this release.
Performance Optimizations:
- Non-blocking Cache Writes: Cache misses no longer block query responses. Data is written to the cache asynchronously after the query returns, reducing query latency for cache miss scenarios.
- Batch Cache Writes: Multiple cache entries are now written in batches rather than individually, significantly improving write throughput for high-volume cache operations.
Reliability Fixes:
- Correct SWR Refresh Behavior: The stale-while-revalidate (SWR) pattern now correctly refreshes only the specific entries that were accessed instead of refreshing all stale rows in the dataset. This prevents unnecessary source queries and reduces load on upstream data sources.
- Deduplicated Refresh Requests: Fixed an issue where JSON array responses could trigger multiple redundant refresh operations. Refresh requests are now properly deduplicated.
- Fixed Cache Hit Detection: Resolved an issue where queries that didn't include
fetched_at in their projection would always result in cache misses, even when cached data was available.
- Unfiltered Query Optimization:
SELECT * queries without filters now return cached data directly without unnecessary filtering overhead.
For more details, refer to the Caching Acceleration Mode Documentation.
- Added JSON nesting for DynamoDB Streams
- Proper batch deletion handling
Query data sources directly via URL in SQL without prior dataset registration. Supports S3, Azure Blob Storage, and HTTP/HTTPS URLs with automatic format detection and partition inference.
Supported Patterns:
- Single files:
SELECT * FROM 's3://bucket/data.parquet'
- Directories/prefixes:
SELECT * FROM 's3://bucket/data/'
- Glob patterns:
SELECT * FROM 's3://bucket/year=*/month=*/data.parquet'
Key Features:
- Automatic file format detection (Parquet, CSV, JSON, etc.)
- Hive-style partition inference with filter pushdown
- Schema inference from files
- Works with both SQL and DataFrame APIs
Example with hive partitioning:
SELECT * FROM 's3://bucket/data/' WHERE year = '2024' AND month = '01'
Enable via spicepod.yml:
runtime:
params:
url_tables: enabled
New asynchronous query APIs for long-running queries in cluster mode:
/v1/queries endpoint: Submit queries and retrieve results asynchronously- Arrow Flight async support: Non-blocking query execution via Arrow Flight protocol
Enhanced Dashboards: Updated Grafana and Datadog example dashboards with:
- Snapshot monitoring widgets
- Improved accelerated datasets section
- Renamed ingestion lag charts for clarity
Additional Histogram Buckets: Added more buckets to histogram metrics for better latency distribution visibility.
For more details, refer to the Monitoring Documentation.
- Model Listing: New functionality to list available models across multiple AI providers
- DuckDB Partitioned Tables: Primary key constraints now supported in partitioned DuckDB table mode
- Post-refresh Sorting: New
on_refresh_sort_columns parameter for DuckDB enables data ordering after writes
- Improved Install Scripts: Removed jq dependency and improved cross-platform compatibility
- Better Error Messages: Improved error messaging for bucket UDF arguments and deprecated OpenAI parameters
No breaking changes.
New ScyllaDB Data Connector Recipe: New recipe demonstrating how to use ScyllaDB Data Connector. See ScyllaDB Data Connector Recipe for details.
New SMB Data Connector Recipe: New recipe demonstrating how to use ScyllaDB Data Connector. See SMB Data Connector Recipe for details.
The Spice Cookbook includes 86 recipes to help you get started with Spice quickly and easily.
To upgrade to v1.11.0-rc.2, use one of the following methods:
CLI:
Homebrew:
brew upgrade spiceai/spiceai/spice
Docker:
Pull the spiceai/spiceai:v1.11.0-rc.2 image:
docker pull spiceai/spiceai:v1.11.0-rc.2
For available tags, see DockerHub.
Helm:
helm repo update
helm upgrade spiceai spiceai/spiceai
AWS Marketplace:
Spice is available in the AWS Marketplace.

