Spice v2.1.0 (Jul 9, 2026)

Spice v2.1.0 is now available! 🎉
Spice v2.1.0 is the next minor release of Spice, headlined by high-throughput Cayenne CDC, scaling and resilience improvements to PostgreSQL logical replication, expanded distributed query with Iceberg catalog scans and broadcast joins, and the upgrade to DataFusion v54 (including v53), Arrow v58.3, and Vortex v0.74. The release also adds experimental adaptive self-tuning for the Cayenne accelerator, distributed GLM inference, and a range of security, search, and connector improvements.
Highlights in v2.1.0 include:
- High-Throughput Cayenne CDC — in-memory CDC tier, dedicated compaction runtime, and write-path optimizations that cut replication lag on high-volume CDC workloads
- PostgreSQL Replication at Scale — multiple
changes-mode datasets share a single replication slot, unchanged-TOAST recovery, and resilient reconnects across rolling deploys - Distributed Query — distributed Ballista scans of Iceberg catalog tables, broadcast joins for small dimension tables, and shared scheduler job state with failover
- DataFusion v54 — upgrade to DataFusion v54 (folding in v53), Arrow v58.3, and Vortex v0.74, bringing faster joins, scans, and planning
- Adaptive Self-Tuning (Experimental) — opt-in closed-loop tuning and maintained aggregates that adapt Cayenne to hardware, schema, and live workload
What's New in v2.1.0
High-Throughput Cayenne CDC
A major focus of v2.1 is Spice Cayenne write-path throughput for change-data-capture (HTAP) workloads:
- In-Memory CDC Tier: A new in-memory CDC tier and follow-ups cut replication lag on hot upsert tables, with bounded mem-tier checkpointing and O(1) per-scan deletion views, plus a two-phase off-fence checkpoint on the ingest path.
- Dedicated Compaction Runtime: A dedicated compaction runtime with CDC pipelining and protected snapshots isolates compaction from query and ingest paths, with parallelized deletion-vector writes, per-batch directory-barrier coalescing, and size-aware parallel encode for protected-snapshot compaction.
- Incremental Protected Snapshot Compaction: Incremental compaction of protected snapshots (used in Cayenne's merge-on-read deletion index) reduces disk usage and improves query performance.
- Smaller WAL & Metadata-Only Publish:
cayenne_insert_recordtable IDs are stored as 16-byte raw-UUID BLOBs, cutting CDC WAL volume ~34%; upsert commits publish metadata-only, dropping per-key insert records; transient staged CDC deltas are light-encoded. - Delta-Write Encoding Levels: A new
cayenne_delta_encodingsetting (defaultauto) selects delta-write encoding, andcayenne_compression_strategy: zstdis now fully wired. - In-Memory CDC Sharding: PK-hash intra-apply sharding parallelizes in-memory CDC apply.
- Scan Safety Under Write: In-flight scans are ref-counted so snapshot GC can't delete Vortex files mid-read; in-RAM scan parallelism, query admission control, and sound scan output ordering improve read behavior under sustained CDC.
Delta-write encoding effort and Vortex compression are tunable per accelerator. cayenne_delta_encoding: auto (the default) size-gates fresh CDC/append writes — small deltas use a light scheme and are re-encoded during compaction — or pin an explicit level 0..10 (7 is the full default cascade); cayenne_compression_strategy selects the Vortex compression:
acceleration:
engine: cayenne
refresh_mode: changes
params:
cayenne_delta_encoding: auto # 'auto' (default), or pin a level 0..10 (7 = full cascade)
cayenne_compression_strategy: zstd # 'btrblocks' (default) or 'zstd'
Change Data Capture & HTAP
PostgreSQL logical replication (CDC, refresh_mode: changes, introduced in v2.0) gets significant scaling and resilience work in v2.1:
- Shared Replication Slot: Multiple
refresh_mode: changesPostgreSQL datasets on the same connection can name the samepg_replication_slotto share a single replication slot, walsender decoder, and publication, with decoded changes multiplexed by(schema, table)to each dataset. This collapses the slot count from one-per-dataset to one — staying well under Postgres's defaultmax_replication_slots = 10.
datasets:
- from: postgres:public.orders
name: orders
params:
pg_db: mydb
pg_replication_slot: spice_cdc # shared slot name
acceleration:
refresh_mode: changes
- from: postgres:public.customers
name: customers
params:
pg_db: mydb
pg_replication_slot: spice_cdc # same name -> one slot, walsender & publication
acceleration:
refresh_mode: changes
- Unchanged-TOAST Recovery: Under
REPLICA IDENTITY FULL, when anUPDATEleaves a large TOASTed column unchanged, pgoutput sends an "unchanged" marker; Spice now fills that value from the old tuple — its old value is its current value — so updates no longer error or drop columns. Without an old tuple, the error persists with a hint to enableREPLICA IDENTITY FULL. - Transient Walsender Contention: Slot-contention errors during rolling deploys —
SQLSTATE 55006("replication slot is active for PID") and53300("requested standby connections exceeds max_wal_senders") — are now classified as transient and retried with backoff instead of fatally terminating the stream. Replication connections are also released at shutdown start (not process exit), freeing walsender seats for replacement instances. - Strict CDC Param Validation: PostgreSQL CDC parameters are strictly validated rather than silently defaulted.
- Debezium Schema Evolution: Fixes for Debezium schema-evolution support, including tombstone-message handling and sign-extension of minimal-width base64 decimals.
Distributed Query
Distributed Query gains:
- Distributed Iceberg Catalog Scans: Ballista distributes scans of Iceberg catalog tables across executors.
- Broadcast Joins: Small dimension tables are broadcast to executors for distributed joins.
- Shared Scheduler Job State with Failover: Ballista job state is shared so the scheduler can fail over without losing in-flight work.
Performance & Query Engine
Apache DataFusion is upgraded to v54, folding in v53, alongside Arrow v58.3 and Vortex v0.74 (with a pin bump adding intra-file decode split and a per-execution kernel cache). Two DataFusion releases land in this upgrade:
- DataFusion v54 (release notes): adds
LATERALjoins, SQL lambda functions (x -> exprwitharray_transform/array_filter/array_any_match), spilling nested-loop joins, and a fasterarrow-avroreader. Performance work includes morsel-driven Parquet scans (up to ~2x faster for skewed scans), 20-50x faster sort-merge semi/anti/mark joins, redundant-sort-key pruning, NDV-based cardinality estimation, andinner_product/cosine_distancefunctions. - DataFusion v53 (release notes): adds
LIMIT-aware Parquet row-group pruning, broader filter pushdown through joins andUNION, nested-field pushdown (get_fieldinto the scan), faster query planning (some plans dropping from ~4-5ms to ~100us), and 42 faster built-in functions.
Federation deny-list enforcement and catalog DDL are restored after the DataFusion upgrades, and a cost-based left-deep join reordering rule is added for Cayenne acceleration.
AI & LLM
- Native GLM Support with Distributed Inference: Native GLM model support with surfaced
reasoning_content, including tensor-parallel GLM inference. Load a GLM model withmodel_type: glm4(glm4moeandglm4moeliteare also supported):
models:
- name: glm
from: huggingface:huggingface.co/THUDM/glm-4-9b-chat
params:
model_type: glm4
For large models, GLM inference can be distributed across nodes (tensor parallelism) via the mistral.rs pure-TCP ring all-reduce backend — no NCCL/system dependency. This is a Spice.ai Enterprise feature requiring the distributed build. Run the same model on each node, changing only node_rank:
models:
- name: glm
from: huggingface:huggingface.co/THUDM/glm-4-9b-chat
params:
model_type: glm4
distributed_backend: ring
nodes: 10.0.4.21,10.0.4.22 # ordered host/IP per rank; the ring backend currently requires exactly 2
node_rank: 0 # rank of THIS node in [0, world_size); rank 0 serves the API. Set node_rank: 1 on 10.0.4.22
- NSQL Context Endpoint: A new
GET /v1/nsql/contextendpoint returns the SQL dialect, dataset schemas (with optional sample rows), and registered functions that Spice injects into natural-language-to-SQL (POST /v1/nsql) requests — useful for inspecting or caching exactly what the model sees:
# Inspect the context injected into /v1/nsql requests (examples_limit default 3, max 100)
curl "http://localhost:8090/v1/nsql/context?include_examples=true&examples_limit=3"
Returns the dialect, per-dataset schema (keys, indexes, searchable columns), the registered function inventory, and sample rows (abbreviated):
{
"context": "# Spice.ai NSQL Context",
"instructions": [
"Write SQL for the Spice runtime, which uses Apache DataFusion with the SQL parser configured for the PostgreSQL dialect.",
"Use table and column descriptions, primary keys, foreign keys, unique constraints, and indexes when choosing joins and filters."
],
"sql": {
"engine": "Apache DataFusion",
"version": "54.0.0",
"dialect": "PostgreSQL",
"parser": "DataFusion SQL parser configured with PostgreSQL dialect"
},
"datasets": [
{
"name": "sales.orders",
"table": "orders",
"description": "Customer orders",
"columns": [
{ "name": "order_id", "data_type": "Int64", "nullable": false, "primary_key": true, "indexed": true },
{ "name": "customer_id", "data_type": "Utf8", "nullable": false, "vector_search": true, "full_text_search": true }
],
"primary_key": ["order_id"],
"foreign_keys": [
{ "columns": ["customer_id"], "foreign_table": "spice.sales.customers", "foreign_columns": ["id"] }
]
}
],
"functions": {
"summary": "Spice SQL runs on Apache DataFusion ... Run SELECT * FROM list_udfs() to inspect the full registered function inventory",
"search": [
{ "name": "vector_search", "syntax": "vector_search(dataset, 'query text'[, column])" },
{ "name": "text_search", "syntax": "text_search(dataset, 'query text'[, column])" }
]
},
"samples": [
{ "title": "Example rows for `sales.orders`", "content": "| order_id | customer_id |\n| --- | --- |\n| 42 | CUST-1 |" }
]
}
Search & Vectors
- S3 Vectors Pagination:
QueryVectorspaginates for top-K up to 10,000. - Elasticsearch kNN Candidate Pool: The default kNN candidate pool is raised from 10 to 1000 for better recall.
SQL & Query Engine
- FlightSQL Substrait Plans:
CommandStatementSubstraitPlansupport. - Large Result Streaming: Flight streaming is optimized for large result sets.
- Write Authorization: The SQL tool allows writes for ReadWrite API keys.
- Schema Evolution Policies:
on_schema_changesupports widening-only evolution and adrop_and_recreatepolicy.
Security & Connectors
- Kafka mTLS: Mutual TLS configuration is surfaced in the Kafka data connector.
- Secret Resolution at Startup: Secret references are checked and reported at startup.
- DuckDB HNSW: Upgrade to DuckDB v1.5.3 with the statically linked VSS (HNSW) vector extension.
Adaptive Self-Tuning (Experimental)
The Spice Cayenne accelerator gains experimental opt-in self-tuning. cayenne_tuning: auto derives configuration from the detected hardware and inferred schema, while adaptive additionally runs a per-table closed-feedback controller that adapts flush caps, the in-memory CDC tier, compaction cadence, and write concurrency toward operator SLOs (replication lag, freshness, query latency, queries-per-hour). Cayenne can also maintain aggregates incrementally — with predicate-aware delta serving and incremental retraction — and fold whole-table SUM/AVG/COUNT/MIN/MAX from statistics. These features are experimental and disabled by default.
datasets:
- from: postgres:public.orders
name: orders
acceleration:
engine: cayenne
refresh_mode: changes
params:
cayenne_tuning: adaptive # 'auto' (static, env- + schema-derived) or 'adaptive' (closed-loop)
Observability
- Per-Dataset Query Attribution: The
query_executionsmetric gains adatasetsdimension. - HTAP Diagnostics: Improved HTAP replication diagnostics on non-convergence.
- Cayenne Write Observability: Write-phase observability for the in-memory CDC tier.
Notable Bug Fixes
- Cayenne Utf8View: The Utf8View read schema avoids a hash-join offset overflow.
- Cayenne metastore:
cayenne_metastore: tursois honored for partitioned tables and the dataset checkpoint. - Dual-write detection: Dual-write accelerated tables are detected behind the metadata-enrichment wrapper.
digest_manycollisions: Values are length-prefixed so column boundaries can't collide.- Turso WAL checkpoint: WAL checkpoints route through the native Turso connection.
- TLS status probe: The status check probes the metrics endpoint over HTTPS when TLS is enabled.
- Search snippet offsets: Character chunk offsets persist so search snippets aren't shifted or garbled.
- Async query chunk offsets:
/v1/querieschunkrow_offsetuses the cumulative offset rather thanchunk_index * chunk_size.
Dependency Updates
| Dependency / Component | Version |
|---|---|
| DataFusion | v54 |
| Arrow (arrow-rs) | v58.3 |
| Vortex | v0.74 |
| iceberg-rust | v0.9.1 |
| DuckDB | v1.5.3 |
| Rust toolchain | v1.95.0 |
Contributors
- @bjchambers
- @ewgenius
- @Jeadie
- @krinart
- @lukekim
- @melks
- @mvanhorn
- @Oxygen56
- @peasee
- @phillipleblanc
- @sgrebnov
- @v1gnesh
Breaking Changes
No breaking changes.
Cookbook Updates
No new cookbook recipes.
The Spice Cookbook includes more than 100 recipes to help you get started with Spice quickly and easily.
Upgrading
To upgrade to v2.1.0, use one of the following methods:
CLI:
spice upgrade
Homebrew:
brew upgrade spiceai/spiceai/spice
Docker:
Pull the spiceai/spiceai:2.1.0 image:
docker pull spiceai/spiceai:2.1.0
For available tags, see DockerHub.
Helm:
helm repo update
helm upgrade spiceai spiceai/spiceai --version 2.1.0
AWS Marketplace:
Spice is available in the AWS Marketplace.
What's Changed
Changelog
- Make DuckDB schema cast logic more robust by @sgrebnov in #10991
- perf(cayenne): reduce allocation overheads in hot paths by @lukekim in #10950
- improve error message for 'params.spiceai_region' by @Jeadie in #10954
- fix(acceleration): rename WriteMode variants to fix #10960 by @phillipleblanc in #10974
- add Scylla, bigquery and turso to throughput benchmarking by @Jeadie in #11006
- deps(ballista): pull in shuffle-on-object-store correctness fixes (datafusion-ballista PRs #42 + #43) by @phillipleblanc in #10919
- fix(kafka): seek to sidecar offsets via post_rebalance callback on restart by @ewgenius in #11007
- Propagate source comments into schema metadata by @lukekim in #10944
- feat(chbench-driver): better alignment to BenchBase by @sgrebnov in #11012
- fix: handle EXISTS/NOT EXISTS subqueries in federation analyzer by @sgrebnov in #10996
- Enable filter pushdown in spicepod defined UDTFs by @Jeadie in #11004
- Refactor spice dataset configuration command by @Jeadie in #10999
- fix: ensure HashJoinExec partition counts match when join input is statically empty by @phillipleblanc in #11025
- feat(chbench): Improve OLTP throughput and reduce PostgreSQL CDC overhead by @sgrebnov in #11018
- feat(cluster): add distributed query observability metrics by @phillipleblanc in #10990
- fix: delegate truncate in PolyTableProvider to inner write provider by @claudespice in #11036
- Remove default runtime features - enable explicitly in spiced by @phillipleblanc in #11037
- fix: preserve field and schema metadata in Vortex physical schema calculation by @claudespice in #11013
- Expose metadata descriptions via PostgreSQL UDFs by @lukekim in #11032
- fix: route Turso WAL checkpoint through native turso connection (fixes #10657) by @claudespice in #11048
- fix: add missing truncate delegation and guards for wrapper TableProviders by @claudespice in #11014
- Update DataConnector statuses by @krinart in #11052
- remove redundant readonly checks by @Jeadie in #10975
- Fix Unity Catalog connector compatibility with OSS Unity Catalog by @ewgenius in #11026
- refactor(cdc): reduce CDC sub-batch splits for interleaved upsert/delete workloads by @sgrebnov in #11051
- feat(cayenne): allow inline writes with pending deletions (deletes/upserts) by @sgrebnov in #11031
- fix(sql-tool): defer read-only gate to caller's API key role by @phillipleblanc in #11040
- fix: map Gemini Recitation finish reason to ContentFilter by @claudespice in #11046
- feat(cayenne): fast-path CDC deletes by extracting PK values from filters by @sgrebnov in #11049
- fix(cluster): gate scheduler readiness on executor partition loads by @phillipleblanc in #10992
- fix(snowflake): enforce function deny-list in federation pushdown by @claudespice in #11057
- perf(cdc): Last-write-wins dedup in
group_into_sub_batchesto reduce sub-batch splits by @sgrebnov in #11059 - [Bug] Timing between reconnect and AllocateInitialPartitions leaves connection without flight_sql_client by @Jeadie in #10805
- Define 'trait QueryEngine' to refactor runtime crate by @Jeadie in #11028
- fix(snowflake): apply Spice function deny-list in extracted connector crate by @claudespice in #11071
- perf(cayenne): keep CDC upsert PK keysets resident to avoid per-batch full-table rebuilds by @lukekim in #11074
- fix(postgres-replication): emit recovery log + reduce reconnect-warn volume by @claudespice in #11084
- fix metadata on search indexing by @Jeadie in #11080
- perf(cayenne): scale CDC inline flush caps with memory + storage class by @lukekim in #11087
- feat(cayenne): merge-on-read position deletes for PK upsert tables + memory-pool accounting by @lukekim in #11085
- Support tuple-IN composite PK extraction in Cayenne delete fast-path by @sgrebnov in #11093
- feat(cluster): report per-executor table statistics so distributed JoinSelection can size joins by @phillipleblanc in #11089
- feat(cluster): NDV-aware executor stats so CDC q18 join swap fires by @phillipleblanc in #11098
- Improve HTAP replication diagnostics on non-convergence by @sgrebnov in #11100
- Normalize
DataType::NulltoInt32in acceleration schema for duckdb by @krinart in #11062 - Fix debezium schema evolution support by @ewgenius in #11095
- feat(cayenne): incremental write-path executor statistics for distributed join sizing by @phillipleblanc in #11104
- fix(cache): periodic moka maintenance to drain invalidation predicates (#11077) by @phillipleblanc in #11106
- fix: validate Snowflake account identifiers and auth config by @Jeadie in #11024
- fix: trace external mcp server tool calls by @ewgenius in #11058
- Remove unwrap from test code; drop clippy::unwrap_used suppressions by @phillipleblanc in #11108
- Upgrade to DuckDB 1.5.3 + statically link the VSS (HNSW) extension by @sgrebnov in #11107
- Fix fetched_at for HTTP connector by @Jeadie in #11116
- fix(search): propagate LIMIT to base TableScan in VectorScanTableProvider (fixes #8368) by @claudespice in #11124
- feat(runtime): add spicebench feature to register the Cayenne catalog connector by @phillipleblanc in #11122
- fix(cayenne): tombstone inline-checkpointed rows on upsert to prevent duplicate PKs by @sgrebnov in #11129
- Remove possibility of a deadlock in
RuntimeStatusby @krinart in #11114 - Fix Windows build: vendored-vss duckdb-rs + adapt to table-providers mongodb API by @phillipleblanc in #11140
- localpod: synchronize child refreshes when parent uses in-memory (arrow) accelerator by @phillipleblanc in #11139
- Add
datasetsdimension to thequery_executionsmetric by @phillipleblanc in #11138 - fix(spiceai): keep correlated subqueries out of JOIN ON for Spice Cloud federation by @phillipleblanc in #11143
- fix(duckdb): normalize timestamp columns to microsecond precision (fixes #10627) by @claudespice in #11145
- feat(cayenne): sharded parallel Vortex encode with key/time clustering by @lukekim in #11144
- fix(cluster): prevent DoPut write pipeline self-deadlock under ingest backpressure by @phillipleblanc in #11160
- feat(chbench): configurable HTAP concurrency, DuckDB query overrides, and OLTP rate control by @sgrebnov in #11162
- fix(http): preserve non-JSON response rows instead of crashing nested decomposition (fixes #11155) by @claudespice in #11161
- Use declared schema in DynamoDB/MongoDB/Debezium by @krinart in #11066
- fix(cluster): prevent partitioned datasets from staying Refreshing by @phillipleblanc in #11157
- fix(runtime): don't list
postgresas a valid accelerator engine whenpostgres-accelis disabled by @sgrebnov in #11169 - fix(spark): recover stale or broken Spark Connect sessions on failure by @lukekim in #11171
- fix(secrets): don't abort secret lookup precedence walk on a failing store by @phillipleblanc in #11175
- feat(cayenne): bound aggregate write concurrency, conservative defaults, and write/read observability by @lukekim in #11170
- feat(unity_catalog): support Unity Catalog credential vending for Delta Lake tables by @phillipleblanc in #11180
- fix(secrets): keep failed secret stores registered so lookups report the init root cause by @phillipleblanc in #11181
- fix(debezium): sign-extend minimal-width base64 decimals instead of zero-padding by @claudespice in #11184
- fix(deps): update hickory-resolver to 0.26 (evicts hickory-proto 0.25.x) by @phillipleblanc in #11183
- refactor(secrets): derive secret store metadata from a single registry table by @phillipleblanc in #11188
- perf(cayenne): cut CDC replication lag on hot upsert tables by @lukekim in #11191
- feat(cayenne): async inline-fallback (per-tombstone published flag) + 64c/256GB tuning by @lukekim in #11194
- Add HTTP connector mTLS support by @lukekim in #11127
- feat(snowflake): push AT TIME ZONE as CONVERT_TIMEZONE and pin session to UTC by @lukekim in #11190
- feat(cdc): make cdc_max_coalesce_age_ms a real apply-loop linger by @sgrebnov in #11196
- feat(cayenne): delta-write encoding levels (cayenne_delta_encoding, default auto) + make compression_strategy=zstd real by @lukekim in #11199
- Add NSQL context endpoint by @lukekim in #11075
- fix(federation): respect the Spice function deny-list across all SQL connectors; dialect-aware DuckDB pushdown by @claudespice in #11186
- fix: surface unknown/applied cayenne_* runtime.params at startup (fixes #10970) by @claudespice in #11133
- perf(cayenne): plain-fsync ordering tier on the staged-commit hot path by @lukekim in #11198
- fix(kafka): decode JSON payloads to Arrow directly — fixes lossy Decimal128 + removes double-parse (#11192) by @claudespice in #11207
- feat(cayenne): self-tuning accelerator — hardware + schema + closed-loop adaptive (auto/adaptive modes) by @lukekim in #11213
- perf(cayenne): CDC throughput — SF-100 @10K txn/s toward <5s lag + 5K QPH by @lukekim in #11206
- fix(cluster): distribute accelerated tables wrapped by metadata/index providers by @phillipleblanc in #11226
- Improve Cayenne adaptive tuning and schema safety by @lukekim in #11237
- feat: Add cayenne_file_pruning param by @peasee in #11239
- Debezium connector - handle tombstone messages in kafka topic, with schema evolution enabled by @ewgenius in #11197
- feat(cayenne): broadcast small-dimension joins to executors by @phillipleblanc in #11245
- fix: scope request context across the managed query runtime by @phillipleblanc in #11253
- fix: Strip inference columns from table schema on query by @peasee in #11251
- fix(flightsql): don't drop un-pushed FilterExec predicates in distributed pushdown rules by @claudespice in #11256
- feat(postgres): share one replication slot across multiple changes-mode datasets by @phillipleblanc in #11255
- Upgrade to DataFusion v53.1, Arrow v58.3, Vortex v0.74, and dependencies by @lukekim in #11118
- feat(connectors): support file_format: vortex everywhere parquet is supported by @lukekim in #11282
- perf(cayenne): metadata-only publish — drop per-key insert records on upsert commit by @lukekim in #11260
- fix(kafka): harden fetch_latest_message for multi-partition topics by @ewgenius in #11285
- perf(cayenne): bound mem-tier checkpoint churn + O(1) per-scan deletion view by @lukekim in #11249
- fix(udfs): length-prefix digest_many values so column boundaries can't collide (fixes #11272) by @claudespice in #11288
- fix: restore federation deny-list enforcement regressed by the DataFusion 53 upgrade by @claudespice in #11294
- fix(postgres): recover unchanged-TOAST columns from the old tuple; classify walsender contention as transient by @phillipleblanc in #11293
- feat: deepen extended schema inference and wire it into cayenne compaction sharding/sorting by @lukekim in #11284
- perf(cayenne): in-memory CDC tier follow-ups + write-phase observability by @lukekim in #11278
- Support per-dataset CDC tunable overrides by @sgrebnov in #11295
- feat(cayenne): harden adaptive auto-tuner (controller hygiene, mem-tier actuator, delete/burst signals, single opt-in) by @lukekim in #11302
- fix(cayenne): scan inlined-view capture starvation under sustained CDC (analytical QPH) by @lukekim in #11299
- fix(vortex): don't row-evaluate hash-join dynamic filters in the scan by @sgrebnov in #11307
- fix(deps): bump rust-postgres crates (RUSTSEC-2026-0178/0179) by @lukekim in #11313
- fix: strict validation of Postgres CDC params instead of silent defaults (fixes #11274) by @claudespice in #11304
- fix(duckdb): always quote on-refresh sort columns so reserved-word names don't break refresh by @claudespice in #11305
- feat(flightsql): fall back to original connection when endpoint location is unreachable by @melks in #11287
- perf(cayenne): light-encode transient staged CDC deltas by @lukekim in #11311
- feat(acceleration): widening-only schema evolution via on_schema_change by @lukekim in #11261
- deps(vortex): bump pin to spiceai-53 HEAD — intra-file decode split + per-execution kernel cache by @lukekim in #11314
- feat(github): enhance GitHub component validation and error handling by @lukekim in #11259
- feat(cayenne): goal-driven adaptive tuning toward operator SLOs (lag, freshness, query latency, QPH) by @lukekim in #11310
- fix(cayenne): broadcast-join rewrite must bail on ambiguous columns, NULL-equal joins, and residual filters by @claudespice in #11252
- Add Cayenne maintained aggregates by @lukekim in #11235
- perf(cayenne): single-hash composite deletion filter via KeyDeletionIndex::get_batch by @phillipleblanc in #11325
- fix(Vortex): decline only the
InListmembership conjunct of hash-join dynamic filters by @sgrebnov in #11335 - fix: scope SQL UDF arg inlining to args-table columns (fixes #11273) by @claudespice in #11337
- fix(refresh): restore S3 ETag/Version refresh-skip behind provider wrappers by @phillipleblanc in #11339
- fix(cayenne): ref-count in-flight scans so GC can't delete Vortex files mid-read by @phillipleblanc in #11321
- fix(runtime): retry object-store dataset load when source files are not yet available by @phillipleblanc in #11342
- feat(s3): default to path-style for dotted bucket names on standard AWS by @phillipleblanc in #11347
- fix(runtime): resolve accelerated table through metadata-enrichment wrapper by @phillipleblanc in #11345
- fix: detect dual-write accelerated tables behind the metadata-enrichment wrapper by @claudespice in #11351
- feat(cayenne): incremental seq-prefix bake — shrink the merge-on-read deletion index by @lukekim in #11326
- fix(adbc): prevent Spice-specific UDFs from being pushed down to ADBC sources by @krinart in #11297
- fix: Query Redshift schema details from svv_redshift tables by @peasee in #11362
- perf(cayenne): tune Turso connection PRAGMAs + jitter metastore retries by @lukekim in #11359
- Upgrade to DataFusion 54 by @sgrebnov in #11360
- feat(runtime): dedicated CDC-apply tokio runtime + per-runtime tokio metrics by @lukekim in #11370
- fix(cayenne): spill oversized hash joins via sort-merge to avoid OOM by @lukekim in #11371
- fix(cayenne): honor cayenne_metastore: turso for partitioned tables and the dataset checkpoint by @phillipleblanc in #11365
- perf(cayenne): in-RAM scan parallelism, query admission control, skip no-op deletion encode, sound scan output_ordering by @lukekim in #11332
- fix(catalog): restore DDL after DataFusion 54 broke transparent catalog-provider downcasts by @phillipleblanc in #11375
- feat(flightsql): infer schema via SELECT * LIMIT 1 when GetTables is unimplemented by @melks in #11286
- fix(cayenne): Utf8View read schema avoids hash-join offset overflow by @lukekim in #11379
- feat(cluster): support distributed (Ballista) scans of Iceberg tables by @phillipleblanc in #11378
- feat(optimizer): cost-based left-deep join reordering for Cayenne acceleration by @sgrebnov in #11377
- cli - fix service-account auth in
spice cloud *commands by @ewgenius in #11316 - fix: Support external Redshift table schema inference and Hive external type parsing by @peasee in #11399
- feat(llms): native GLM support — opt-in flash-attn + surface reasoning_content by @lukekim in #11400
- feat(s3_vectors): paginate QueryVectors for topK up to 10,000 by @bjchambers in #11405
- fix: surface .env parse errors with line numbers instead of silently skipping by @Oxygen56 in #11306
- fix(status): probe metrics endpoint over https when TLS is enabled by @phillipleblanc in #11393
- fix(mcp): record task_history spans for tool calls proxied through /v1/mcp by @phillipleblanc in #11397
- Properly handle date_trunc in BigQueryDialect by @krinart in #11416
- fix(snowflake): honor column scale in Int64 timestamp arm and cast TIME by @claudespice in #11418
- fix: /v1/queries chunk row_offset uses cumulative offset, not chunk_index * chunk_size (fixes #11271) by @claudespice in #11398
- feat(cayenne): incremental retraction for maintained aggregates + anchor bench by @lukekim in #11389
- feat(cluster): support distributed (Ballista) scans of Iceberg catalog tables by @phillipleblanc in #11419
- Simplify chat/responses models by @Jeadie in #10997
- feat(llms): distributed tensor-parallel GLM inference via mistral.rs ring backend by @lukekim in #11406
- Optimize Flight streaming for large result sets by @lukekim in #11420
- fix(deps): evict rustls 0.21 / rustls-webpki 0.101.7 (GHSA-82j2-j2ch-gfr8) by @phillipleblanc in #11428
- feat(cayenne): in-memory CDC intra-apply sharding (PK-hash shards) by @lukekim in #11421
- fix(cayenne): shard CDC upserts with pending deletions so the N>1 slot-ack advances by @lukekim in #11445
- fix(cluster): keep built-in avg over Spark avg (distributed aggregate state schema mismatch) by @phillipleblanc in #11434
- feat(views): support params.file_format for embedding chunking by @Jeadie in #11424
- fix: offload blocking sync calls off the primary async runtime by @phillipleblanc in #11435
- fix(udfs): rebind dot_product alias to Spice's inner_product on DataFusion 54 by @lukekim in #11443
- feat(secrets): add full-fidelity reference iteration and a resolution-status API by @phillipleblanc in #11195
- fix: Deny unsupported array functions for Postgres pushdown by @peasee in #11450
- fix(cli): spice query honors --http-endpoint instead of failing on a Flight connect by @phillipleblanc in #11452
- fix(cayenne): coordinate query-pool + in-memory CDC tier budgets to prevent adaptive OOM by @lukekim in #11449
- Surface mTLS config in Kafka data connector by @v1gnesh in #11372
- feat(secrets): check and report secret references at startup by @phillipleblanc in #11457
- Default cayenne_force_view_types to false by @sgrebnov in #11459
- fix: resolve table-reference qualification in results-cache invalidation (fixes #11266) by @claudespice in #11460
- feat(cayenne): metadata aggregate pushdown — fold whole-table SUM/AVG/COUNT/MIN/MAX from statistics by @bjchambers in #11414
- fix(search): restore numeric trunc and fix SortPreservingMergeExec planning error (DF54) by @Jeadie in #11415
- fix(cluster): route Ballista shuffle/temp to the data PVC by @phillipleblanc in #11454
- fix(search): default Elasticsearch kNN candidate pool to 1000 instead of 10 (fixes #11264) by @claudespice in #11467
- feat(acceleration): add on_schema_change drop_and_recreate policy by @lukekim in #11462
- feat(cayenne): predicate-aware maintained aggregates serve filtered analytical queries from the CDC delta by @lukekim in #11458
- feat(cluster): shared Ballista job state with scheduler failover by @phillipleblanc in #11436
- feat(cayenne): extend HLL NDV sketching to string and date columns by @bjchambers in #11468
- fix(search): persist character chunk offsets so search snippets aren't shifted/garbled (fixes #11269) by @claudespice in #11479
- feat(cayenne): storage-aware adaptive CDC tuning — calibration probe, IMDS, I/O-cliff fast path, infeasible-SLO feedback by @lukekim in #11463
- fix(cayenne): LIMIT N under-delivers on key-deletion tables by @lukekim in #11490
- fix(cayenne): live/tier-accurate join build-side stats (merge-on-read deletes + never-shrink NDV) by @lukekim in #11496
- perf(cayenne): kernel-space I/O hygiene — compaction fadvise + staged-commit barrier reduction by @lukekim in #11495
- feat(cayenne): feed maintained-aggregate IVM from the staged-disk CDC path by @lukekim in #11491
- feat(cayenne): global adaptive-tuning SLOs with per-dataset overrides; QPH global-only by @lukekim in #11497
- Update search snapshots by @sgrebnov in #11473
- fix: Support reading column types longer than 128 chars in Redshift by @peasee in #11500
- fix(cluster): distributed (Ballista) query-execution config + scheduled SF10 bench by @phillipleblanc in #11478
- fix(http): retry transient response-body read failures; de-flake backoff test by @claudespice in #11482
- Re-land orphaned deletion-vector cleanup during retention deletes by @lukekim in #11501
- fix(cayenne): re-upsert over a pending delete tombstone records an insert-record (overwrite resurrection) by @bjchambers in #11469
- fix: Flight DoPut silently dropped client batches on early sink completion by @claudespice in #11507
- Upgrade OpenTelemetry to 0.32 and reqwest to 0.13 by @phillipleblanc in #11506
- fix(queries): run async /v1/queries jobs under the submitting request context by @phillipleblanc in #11505
- fix(cayenne): restore append-only current-snapshot compaction by @Jeadie in #11439
- perf(cayenne): orphaned deletion-vector cleanup off the write path, behind a knob by @bjchambers in #11517
- fix(datafusion): accurate projected scan byte size so hash joins build the smaller side by @sgrebnov in #11503
- fix(cayenne): user-visible DELETE WHERE pk IN (...) reports the real row count by @lukekim in #11514
- fix(cayenne): seed persisted
num_rowsfor hash-join sizing by @sgrebnov in #11515 - fix(cayenne): correctness & memory_limit fixes from perf audit (2 P0, 3 P1) by @lukekim in #11516
- feat(cayenne): wire orphaned-DV cleanup knob to spicepod params + doc sync by @bjchambers in #11523
- Fix s3 vectors API by @krinart in #11536
- fix: Placeholder table initialization lock swap by @peasee in #11540
- chore(cluster): bump ballista pin for the null-aware anti-join fix by @phillipleblanc in #11544
- fix(runtime-tools): fix memory table identifier validation rejecting valid names by @Jeadie in #11546
- Bump datafusion to include spiceai/datafusion#181 by @Jeadie in #11563
- Update deny.toml by @krinart in #11571
- Bump datafusion (spiceai/datafusion#182) and datafusion-table-providers (#27): fix q16 CollectLeft planning error and SQLite q6 wrong revenue by @Jeadie in #11598
Full Changelog: https://github.com/spiceai/spiceai/compare/v2.0.0...v2.1.0



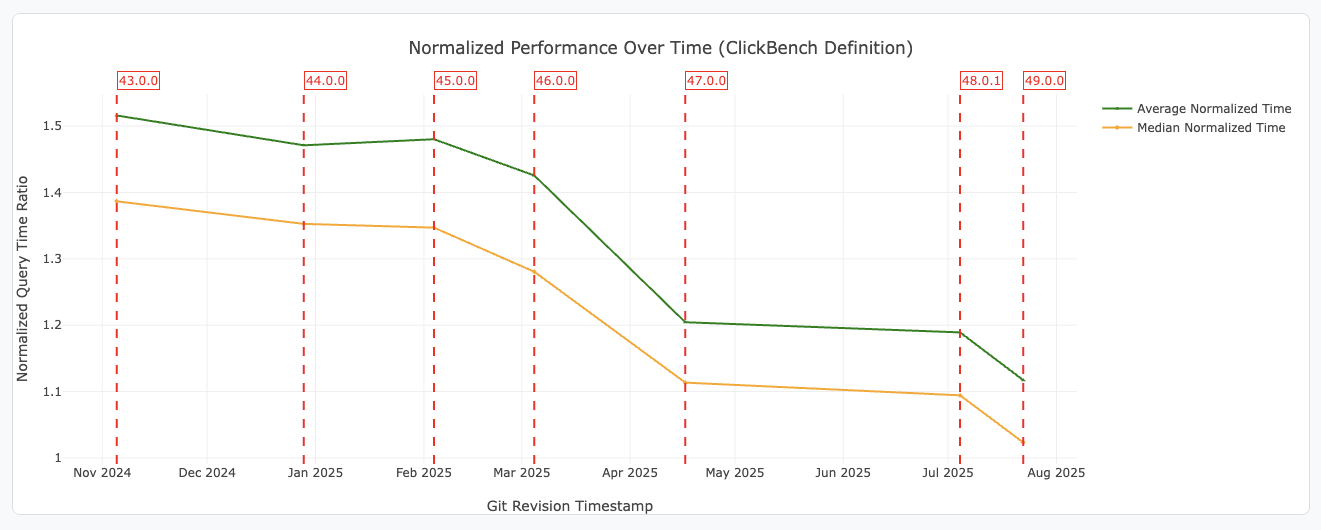 Source:
Source: 